-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Speculation: SYCL will replace CUDA
Page 4 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Vattila
Senior member
Minor quibble, but the GeForce 256 wasn't their first dGPU. It was actually the STG2000. Most of us only remember the Riva 128.
I particularly remember that the TNT series got my attention. I think I bought one of those. Ironically, I was at that time drawn to Nvidia due to their support for open/platform standards (OpenGL/DirectX) versus the proprietary Glide API from 3DFX. Oh, how things have changed!
PS. The GeForce 256 was marketed by Nvidia as "the world's first Graphics Processing Unit". See also Wikipedia | GPU.
Last edited:
DrMrLordX
Lifer
PS. The GeForce 256 was marketed by Nvidia as "the world's first Graphics Processing Unit". See also Wikipedia | GPU.
Well okay. But it doesn't mean their marketing was correct.
Vattila
Senior member
Well okay. But it doesn't mean their marketing was correct.
True, although they popularised the term "GPU" in the PC space, we'll have to admit. Before then we just called it a "3D graphics card" or just a "3D card", didn't we? The buzzword in the 1990s was "3D", I seem to recall.
The more interesting development, though, was the move of more tasks and computational abilities to the graphics card — transform and lighting, etc. — which allowed Ian Buck to "abuse" this functionality to make the graphics card into an accelerator of more general-purpose computations (GPGPU). So the background story of CUDA, as the quoted article tells it (post #75), begins with Ian Buck's PhD work at Stanford University on the Brook programming language in 1999, although he wasn't hired by Nvidia until 2004, and CUDA wasn't introduced until 2006. In between 1999 and 2006 we got programmable shaders and better support for floating-point arithmetic in the hardware, which set the stage for even more general-purpose programmability in CUDA. I remember following the exciting developments in DirectX in this period, although I didn't end up doing much 3D graphics or GPGPU programming, sadly.
"A significant milestone for GPGPU was the year 2003 when two research groups independently discovered GPU-based approaches for the solution of general linear algebra problems on GPUs that ran faster than on CPUs."
Wikipedia
Last edited:
Vattila
Senior member
At the Hot Chips conference, running this week, Intel has shown off some SYCL performance results for their "Ponte Vecchio" server GPU. The latter is a key component of the upcoming Aurora supercomputer. Just as interesting though, is the "A100-SYCL" performance compared to the "A100-CUDA" performance, using Nvidia's A100 GPU. SYCL is very performance portable here — which is remarkable, as the A100-SYCL code is the result of automated migration using Intel's DPC++ Compatibility Tool.
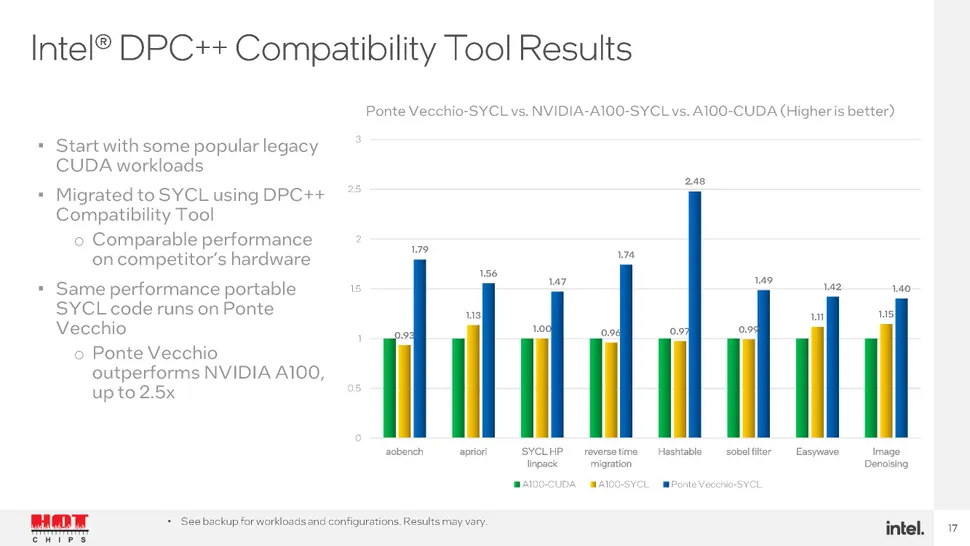
Intel Ponte Vecchio Seemingly Offers 2.5x Higher Performance Than Nvidia's A100 | Tom's Hardware (tomshardware.com)
Intel Ponte Vecchio Seemingly Offers 2.5x Higher Performance Than Nvidia's A100 | Tom's Hardware (tomshardware.com)
Tugrul_8192bit
Junior Member
CUDA has deep roots in industry. Almost irreplacable.
Vattila
Senior member
Still not a word on SYCL from AMD, but HIP — the CUDA dialect serving as a programming model for their ROCm framework — is getting traction in the HPC space:
"Devito is a domain-specific Language (DSL) and code generation framework for the design of highly optimized finite-difference kernels for use in simulation, inversion, and optimization. Devito utilizes a combination of symbolic computation and compiler technologies to automatically generate highly optimized software for a wide range of computer architectures. Previously Devito only supported AMD GPUs using OpenMP offloading. Thanks to Devito Codes’ new collaboration with AMD, we quickly adapted our existing CUDA to also support HIP for AMD GPUs. This resulted in a substantial uplift in performance, achieving competitive levels of performance with comparable architectures."
DevitoPRO getting HIP with AMD Instinct™ | Devito Codes

"Devito is a domain-specific Language (DSL) and code generation framework for the design of highly optimized finite-difference kernels for use in simulation, inversion, and optimization. Devito utilizes a combination of symbolic computation and compiler technologies to automatically generate highly optimized software for a wide range of computer architectures. Previously Devito only supported AMD GPUs using OpenMP offloading. Thanks to Devito Codes’ new collaboration with AMD, we quickly adapted our existing CUDA to also support HIP for AMD GPUs. This resulted in a substantial uplift in performance, achieving competitive levels of performance with comparable architectures."
DevitoPRO getting HIP with AMD Instinct™ | Devito Codes
Vattila
Senior member
Samsung just announced a supercomputer based on their ground-breaking processing-in-memory (PIM) technology in combination with AMD Instinct GPUs — using SYCL as the programming model:
"The supercomputer, disclosed Tuesday at an industry event in South Korea, includes 96 AMD Instinct MI100 GPUs, each of which are loaded with a processing-in-memory (PIM) chip, a new kind of memory technology that reduces the amount of data that needs to move between the CPU and DRAM. Choi Chang-kyu, the head of the AI Research Center at Samsung Electronics Advanced Institute of Technology, reportedly said the cluster was able to train the Text-to-Test Transfer Transformer (T5) language model developed by Google 2.5 times faster while using 2.7 times less power compared to the same cluster configuration that didn't use the PIM chips. [...] Samsung hopes to spur adoption of its PIM chips in the industry by creating software that will allow organizations to use the tech in an integrated software environment. To do this, it's relying on SYCL, a royalty-free, cross-architecture programming abstraction layer that happens to underpin Intel's implementation of C++ for its oneAPI parallel programming model."

 www.theregister.com
www.theregister.com
"The supercomputer, disclosed Tuesday at an industry event in South Korea, includes 96 AMD Instinct MI100 GPUs, each of which are loaded with a processing-in-memory (PIM) chip, a new kind of memory technology that reduces the amount of data that needs to move between the CPU and DRAM. Choi Chang-kyu, the head of the AI Research Center at Samsung Electronics Advanced Institute of Technology, reportedly said the cluster was able to train the Text-to-Test Transfer Transformer (T5) language model developed by Google 2.5 times faster while using 2.7 times less power compared to the same cluster configuration that didn't use the PIM chips. [...] Samsung hopes to spur adoption of its PIM chips in the industry by creating software that will allow organizations to use the tech in an integrated software environment. To do this, it's relying on SYCL, a royalty-free, cross-architecture programming abstraction layer that happens to underpin Intel's implementation of C++ for its oneAPI parallel programming model."
Samsung puts processing-in-memory chip onto AMD MI100 GPU
Korean tech giant claims big performance, energy efficiency gains with memory tech
Vattila
Senior member
CodePlay is making great progress on their support for AMD and Nvidia in oneAPI, all based on the SYCL programming model standard. Despite being an AMD investor, this is one area I'm rooting for Raja Koduri, James Reinders and the other SYCL champions at Intel. In one important sense — standard-based heterogeneous system architectures and programming models — oneAPI is a continuation of the HSA effort started at AMD years ago. (Interestingly, Phil Rogers, former HSA Foundation president and one of AMD's few Corporate Fellows, a distinguished title only bestowed upon their brightest engineers, jumped ship to Nvidia back in 2015.)

 codeplay.com
codeplay.com
Here is The Next Platform's article on the news:
"In a world where the number of chip platforms is rapidly expanding and accelerators from GPUs to FPGAs to DPUs are becoming the norm, being able to use the same tools when programming for the myriad chip architectures has a utopian vibe for many developers. It’s one of the reasons James Reinders returned to Intel just over two years ago after spending more than 27 years at the chip maker before leaving in 2016. It was a chance to help create a technology that could bring benefits to the IT industry, from enterprises out to HPC organizations. [...] OneAPI is seeing some momentum among early adopters – as of a year ago, more than 100 national laboratories, research organizations, educational institutions, and enterprises were using the platform, with Intel pulling in community input and contributions to the oneAPI spec through the open project. There also are now 30 oneAPI Centers of Excellence around the world."
“What will happen when these tools come out is you can download the tools from Intel, but then Codeplay will have a download that … plugs in and adds support for Nvidia GPUs and can plug in and support AMD GPUs,” Reinders says. “To the user, once those are all installed, you just run the compiler and it’ll take advantage of all of them and it can produce a binary – this is what really distinguishes it –that when you run it, if it turns out you have a system with, say, AXV-512 on your CPU, maybe an integrated graphics from Intel, a plug-in graphics from Nvidia, plug-in graphics from AMD, a plug-in from Intel, your program can come up and use all five of them in one run.”
oneAPI 2023: One Plug-In To Run Them All (nextplatform.com)

Codeplay® announces oneAPI for Nvidia® and AMD GPU hardware
Develop using the open, standards-based SYCL™ programming model for multiple accelerators with oneAPI.[Dec. 16, 2022 - Edinburgh, UK] – Today, Codeplay...
Here is The Next Platform's article on the news:
"In a world where the number of chip platforms is rapidly expanding and accelerators from GPUs to FPGAs to DPUs are becoming the norm, being able to use the same tools when programming for the myriad chip architectures has a utopian vibe for many developers. It’s one of the reasons James Reinders returned to Intel just over two years ago after spending more than 27 years at the chip maker before leaving in 2016. It was a chance to help create a technology that could bring benefits to the IT industry, from enterprises out to HPC organizations. [...] OneAPI is seeing some momentum among early adopters – as of a year ago, more than 100 national laboratories, research organizations, educational institutions, and enterprises were using the platform, with Intel pulling in community input and contributions to the oneAPI spec through the open project. There also are now 30 oneAPI Centers of Excellence around the world."
“What will happen when these tools come out is you can download the tools from Intel, but then Codeplay will have a download that … plugs in and adds support for Nvidia GPUs and can plug in and support AMD GPUs,” Reinders says. “To the user, once those are all installed, you just run the compiler and it’ll take advantage of all of them and it can produce a binary – this is what really distinguishes it –that when you run it, if it turns out you have a system with, say, AXV-512 on your CPU, maybe an integrated graphics from Intel, a plug-in graphics from Nvidia, plug-in graphics from AMD, a plug-in from Intel, your program can come up and use all five of them in one run.”
oneAPI 2023: One Plug-In To Run Them All (nextplatform.com)
Last edited:
Vattila
Senior member
Vattila
Senior member
A couple of news items on SYCL:

- The hipSYCL implementation from Heidelberg University has been renamed Open SYCL.
- State of SYCL - ECP BOF Showcases Progress and Performance.
Vattila
Senior member
Not directly related to SYCL, but the just announced OpenXLA compiler project for machine learning (ML) further erodes CUDA's incumbency in the AI/ML space. With this open cross-platform solution for accelerated linear algebra (XLA), the high-level frameworks (that researchers and developers actually use) reduce the ML models down to high-level operations (HLO) in the StableHLO specification, which in turn are compiled by the OpenXLA target-independent optimising compilers, producing MLIR code, which is finally compiled into actual code for the specific target platform. All the important vendors seem to be aboard, including Nvidia:
"OpenXLA is an open source ML compiler ecosystem co-developed by AI/ML industry leaders including Alibaba, Amazon Web Services, AMD, Apple, Arm, Cerebras, Google, Graphcore, Hugging Face, Intel, Meta, and NVIDIA. It enables developers to compile and optimize models from all leading ML frameworks for efficient training and serving on a wide variety of hardware. Developers using OpenXLA will see significant improvements in training time, throughput, serving latency, and, ultimately, time-to-market and compute costs. [...] OpenXLA provides out-of-the-box support for a multitude of hardware devices including AMD and NVIDIA GPUs, x86 CPU and Arm architectures, as well as ML accelerators like Google TPUs, AWS Trainium and Inferentia, Graphcore IPUs, Cerebras Wafer-Scale Engine, and many more. OpenXLA additionally supports TensorFlow, PyTorch, and JAX via StableHLO, a portability layer that serves as OpenXLA's input format."
Notably, on low-level performance tuning, SYCL is mentioned as an option:
""OpenXLA gives users the flexibility to manually tune hotspots in their models. Extension mechanisms such as Custom-call enable users to write deep learning primitives with CUDA, HIP, SYCL, Triton and other kernel languages so they can take full advantage of hardware features."
OpenXLA is available now to accelerate and simplify machine learning | Google Open Source Blog (googleblog.com)

"OpenXLA is an open source ML compiler ecosystem co-developed by AI/ML industry leaders including Alibaba, Amazon Web Services, AMD, Apple, Arm, Cerebras, Google, Graphcore, Hugging Face, Intel, Meta, and NVIDIA. It enables developers to compile and optimize models from all leading ML frameworks for efficient training and serving on a wide variety of hardware. Developers using OpenXLA will see significant improvements in training time, throughput, serving latency, and, ultimately, time-to-market and compute costs. [...] OpenXLA provides out-of-the-box support for a multitude of hardware devices including AMD and NVIDIA GPUs, x86 CPU and Arm architectures, as well as ML accelerators like Google TPUs, AWS Trainium and Inferentia, Graphcore IPUs, Cerebras Wafer-Scale Engine, and many more. OpenXLA additionally supports TensorFlow, PyTorch, and JAX via StableHLO, a portability layer that serves as OpenXLA's input format."
Notably, on low-level performance tuning, SYCL is mentioned as an option:
""OpenXLA gives users the flexibility to manually tune hotspots in their models. Extension mechanisms such as Custom-call enable users to write deep learning primitives with CUDA, HIP, SYCL, Triton and other kernel languages so they can take full advantage of hardware features."
OpenXLA is available now to accelerate and simplify machine learning | Google Open Source Blog (googleblog.com)
Last edited:
Vattila
Senior member
The European Union is investing in RISC-V and SYCL:
"The wide-spread adoption of AI has resulted in a market for novel hardware accelerators that can efficiently process AI workloads. Unfortunately, all popular AI accelerators today use proprietary hardware—software stacks, leading to a monopolization of the acceleration market by a few large industry players. Eight leading European organizations have joined in an effort to break this monopoly via Horizon Europe project SYCLOPS (Scaling extreme analYtics with Cross-architecture acceleration based on Open Standards). The vision of SYCLOPS is to democratize AI acceleration using open standards, and enabling a healthy, competitive, innovation-driven ecosystem for Europe and beyond."
 www.syclops.org
www.syclops.org
"The wide-spread adoption of AI has resulted in a market for novel hardware accelerators that can efficiently process AI workloads. Unfortunately, all popular AI accelerators today use proprietary hardware—software stacks, leading to a monopolization of the acceleration market by a few large industry players. Eight leading European organizations have joined in an effort to break this monopoly via Horizon Europe project SYCLOPS (Scaling extreme analYtics with Cross-architecture acceleration based on Open Standards). The vision of SYCLOPS is to democratize AI acceleration using open standards, and enabling a healthy, competitive, innovation-driven ecosystem for Europe and beyond."
SYCLOPS - Democratizing AI Acceleration Using Open Standards
Democratizing AI Acceleration Using Open Standards
www.syclops.org
Vattila
Senior member
OpenAI's Triton is emerging as an open-source implementation language for neural network AI frameworks, replacing (or at least marginalising) low-level heterogeneous programming models such as CUDA and SYCL. The Triton compiler performs optimisations that are hard to do by hand.
"We’re releasing Triton 1.0, an open-source Python-like programming language which enables researchers with no CUDA experience to write highly efficient GPU code—most of the time on par with what an expert would be able to produce."
Introducing Triton: Open-source GPU programming for neural networks
Triton is now used as a backend for the popular PyTorch 2.0 framework:
"TorchInductor is a deep learning compiler that generates fast code for multiple accelerators and backends. For NVIDIA and AMD GPUs, it uses OpenAI Triton as a key building block. [...] For a new compiler backend for PyTorch 2.0, we took inspiration from how our users were writing high performance custom kernels: increasingly using the Triton language. We also wanted a compiler backend that used similar abstractions to PyTorch eager, and was general purpose enough to support the wide breadth of features in PyTorch. TorchInductor uses a pythonic define-by-run loop level IR to automatically map PyTorch models into generated Triton code on GPUs and C++/OpenMP on CPUs."
PyTorch 2.0 | Get started
Support for AMD hardware in Triton is forthcoming, opening up the options for AI development and deployment:
ROCm 5.6.1 | Release Highlights
GitHub | Triton | [ROCM] Core Functionality for AMD
Here is some further reading on Triton:
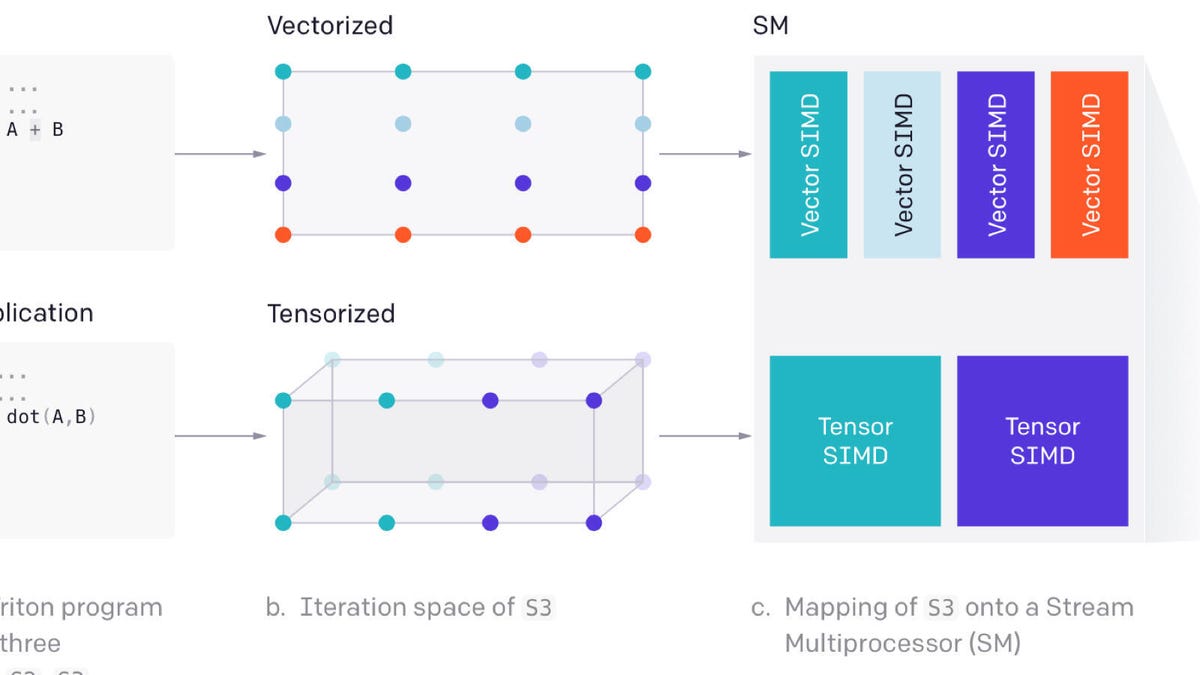
 www.zdnet.com
www.zdnet.com
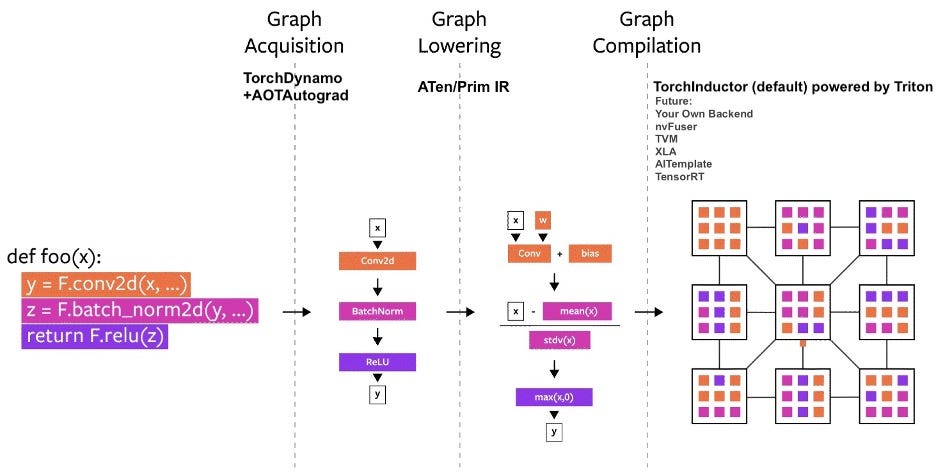
 www.semianalysis.com
www.semianalysis.com
Paper: Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations
"We’re releasing Triton 1.0, an open-source Python-like programming language which enables researchers with no CUDA experience to write highly efficient GPU code—most of the time on par with what an expert would be able to produce."
Introducing Triton: Open-source GPU programming for neural networks
Triton is now used as a backend for the popular PyTorch 2.0 framework:
"TorchInductor is a deep learning compiler that generates fast code for multiple accelerators and backends. For NVIDIA and AMD GPUs, it uses OpenAI Triton as a key building block. [...] For a new compiler backend for PyTorch 2.0, we took inspiration from how our users were writing high performance custom kernels: increasingly using the Triton language. We also wanted a compiler backend that used similar abstractions to PyTorch eager, and was general purpose enough to support the wide breadth of features in PyTorch. TorchInductor uses a pythonic define-by-run loop level IR to automatically map PyTorch models into generated Triton code on GPUs and C++/OpenMP on CPUs."
PyTorch 2.0 | Get started
Support for AMD hardware in Triton is forthcoming, opening up the options for AI development and deployment:
ROCm 5.6.1 | Release Highlights
GitHub | Triton | [ROCM] Core Functionality for AMD
Here is some further reading on Triton:
OpenAI proposes open-source Triton language as an alternative to Nvidia's CUDA
SEO: Python-like language promises to be easier to write than native CUDA and specialized GPU code but has performance comparable to what expert GPU coders can produce and better than standard library code such as Torch.
How Nvidia’s CUDA Monopoly In Machine Learning Is Breaking - OpenAI Triton And PyTorch 2.0
Over the last decade, the landscape of machine learning software development has undergone significant changes. Many frameworks have come and gone, but most have relied heavily on leveraging Nvidia's CUDA and performed best on Nvidia GPUs. However, with the arrival of PyTorch 2.0 and OpenAI's...
www.semianalysis.com
Paper: Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations
moinmoin
Diamond Member
While Triton started with only support for Nvidia GPUs, adoption of support for AMD and Intel GPUs now seems to be under way: https://www.techgoing.com/openai-triton-has-begun-merging-amd-rocm-code/
Vattila
Senior member
SYCL for ground-breaking processing-in-memory (PIM) in the context of AI:

 www.servethehome.com
www.servethehome.com


Samsung Processing in Memory Technology at Hot Chips 2023
At Hot Chips 2023, Samsung showed its Processing in/near Memory ranging from PIM-HBM in AMD MI100 test GPUs to LPDDR-PIM and CXL-PNM modules
Vattila
Senior member
It appears OpenSYCL (formerly known as hipSYCL) has yet again been renamed (due to legal pressure). The new name sounds straight out of AMD's new marketing terms dictionary (strongly influenced by the former Xilinx group). Hopefully AMD will get aboard, if not already.

"AdaptiveCpp is the independent, community-driven modern platform for C++-based heterogeneous programming models targeting CPUs and GPUs from all major vendors. AdaptiveCpp lets applications adapt themselves to all the hardware found in the system. This includes use cases where a single binary needs to be able to target all supported hardware, or utilize hardware from different vendors simultaneously."
"It currently supports the following programming models: (1) SYCL and (2) C++ standard parallelism."
"AdaptiveCpp is currently the only solution that can offload C++ standard parallelism constructs to GPUs from Intel, NVIDIA and AMD — even from a single binary."
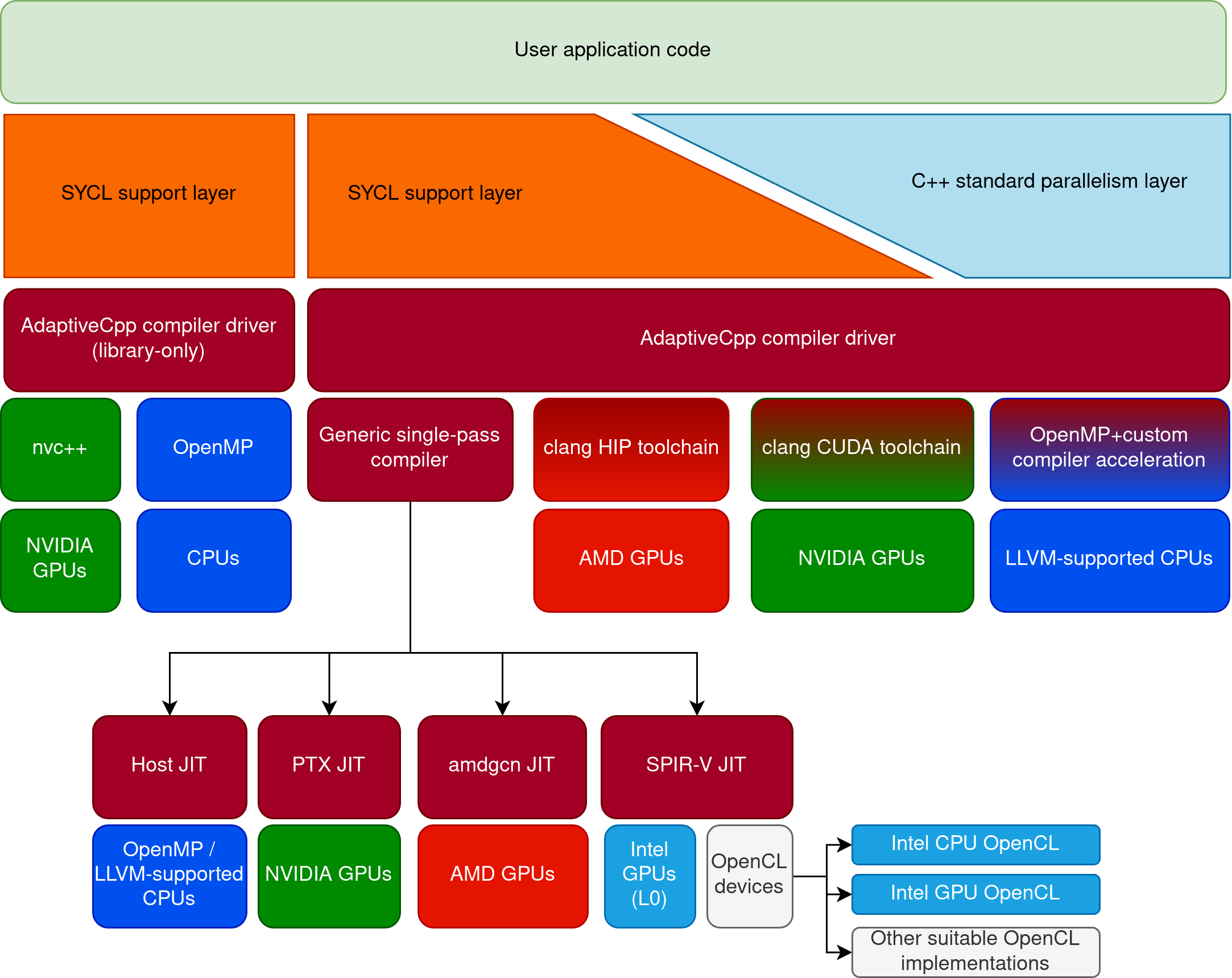
GitHub - AdaptiveCpp
"AdaptiveCpp is the independent, community-driven modern platform for C++-based heterogeneous programming models targeting CPUs and GPUs from all major vendors. AdaptiveCpp lets applications adapt themselves to all the hardware found in the system. This includes use cases where a single binary needs to be able to target all supported hardware, or utilize hardware from different vendors simultaneously."
"It currently supports the following programming models: (1) SYCL and (2) C++ standard parallelism."
"AdaptiveCpp is currently the only solution that can offload C++ standard parallelism constructs to GPUs from Intel, NVIDIA and AMD — even from a single binary."
GitHub - AdaptiveCpp
Last edited:
Seems more like the name change signifies diversification in programming models to include C++ standard parallelism as well as SYCL.It's odd that there would be legal issues about an open Khronos standard. Such efforts ideally should be shared with upstream anyway. Sounds like some member of Khronos wants segmentation there?
Though why they are already splitting their attention when they haven't even got significant software support as yet I don't know.
Vattila
Senior member
It looks like AMD's software stack is coming together at the right time for AI take-off. AMD CEO Lisa Su said years ago that AMD's biggest investments were in software, and we are now seeing it bearing fruit.
PyTorch (the most popular machine learning framework) now comes with AMD ROCm support out of the box.
And DeepSpeed (Microsoft's open-source deep learning optimisation library for PyTorch) is now "hipified", i.e. using AMD's HIP language to provide compatibility with both ROCm and CUDA backends, and to be accepted into the code base, any code changes must now pass AMD compatibility as part of the test suite.
As a reminder, HIP is essentially a dialect of the CUDA programming language, and the ROCm framework is a plug-in replacement for the CUDA framework.
PyTorch (the most popular machine learning framework) now comes with AMD ROCm support out of the box.
And DeepSpeed (Microsoft's open-source deep learning optimisation library for PyTorch) is now "hipified", i.e. using AMD's HIP language to provide compatibility with both ROCm and CUDA backends, and to be accepted into the code base, any code changes must now pass AMD compatibility as part of the test suite.
As a reminder, HIP is essentially a dialect of the CUDA programming language, and the ROCm framework is a plug-in replacement for the CUDA framework.
Last edited:
Vattila
Senior member
While SYCL has seen very little use in AI, it seems CUDA's role within AI is diminishing fast anyway.
Here is an interesting update on Microsoft's Azure infrastructure (the provider of compute resources for OpenAI, ChatGPT, GPT-4, Microsoft Copilot). Apparently, Nvidia (CUDA) does no longer have a moat at this hyperscaler. Using the Triton abstraction layer, Microsoft is now able to seamlessly swap in AMD or Nvidia GPU nodes in their cluster architecture. And, notably, while this cluster architecture is interconnected by Nvidia's InfiniBand, Microsoft's next-generation water-cooled cluster architecture is based on standard Ethernet.

PS. AMD announced yesterday that "Microsoft is using VMs powered by AMD Instinct MI300X and ROCm software to achieve leading price/performance for GPT workloads".
Here is an interesting update on Microsoft's Azure infrastructure (the provider of compute resources for OpenAI, ChatGPT, GPT-4, Microsoft Copilot). Apparently, Nvidia (CUDA) does no longer have a moat at this hyperscaler. Using the Triton abstraction layer, Microsoft is now able to seamlessly swap in AMD or Nvidia GPU nodes in their cluster architecture. And, notably, while this cluster architecture is interconnected by Nvidia's InfiniBand, Microsoft's next-generation water-cooled cluster architecture is based on standard Ethernet.
PS. AMD announced yesterday that "Microsoft is using VMs powered by AMD Instinct MI300X and ROCm software to achieve leading price/performance for GPT workloads".
Last edited:
Vattila
Senior member
Since the AI revolution, the so-called CUDA moat, and how to overcome it, has been even more on my mind.
The "CUDA moat" is significant due to the extensive legacy code spanning many use cases in HPC and AI. There must be millions of lines of CUDA code out there. Much of this code, written by researchers, companies, and individuals, will persist because sticking with Nvidia requires less effort compared to rewriting, however compelling alternatives are. This is similar to other long-standing platforms like x86 and Win32.
That said, while the workloads within the CUDA ecosystem are broad, the most profitable workloads within AI training and inference are relatively narrow and rely on cutting-edge open frameworks like PyTorch, DeepSpeed, and OpenAI's Triton. Notably, PyTorch has supported AMD out-of-the-box since last year, and all open-source models at Hugging Face, the central repository for these models, are continuously tested for AMD compatibility.
AMD's open ROCm software has improved leaps and bounds over the last year. It seems perfectly feasible to me, especially for a company with AMD's resources, to adequately provide the functionality and optimizations needed to overcome the CUDA moat for AI training and inference. It is already happening.
So, while the entire CUDA ecosystem can't be replaced, the high-value, lucrative workloads can definitely be contested, as I see it.
Further reading:
The "CUDA moat" is significant due to the extensive legacy code spanning many use cases in HPC and AI. There must be millions of lines of CUDA code out there. Much of this code, written by researchers, companies, and individuals, will persist because sticking with Nvidia requires less effort compared to rewriting, however compelling alternatives are. This is similar to other long-standing platforms like x86 and Win32.
That said, while the workloads within the CUDA ecosystem are broad, the most profitable workloads within AI training and inference are relatively narrow and rely on cutting-edge open frameworks like PyTorch, DeepSpeed, and OpenAI's Triton. Notably, PyTorch has supported AMD out-of-the-box since last year, and all open-source models at Hugging Face, the central repository for these models, are continuously tested for AMD compatibility.
AMD's open ROCm software has improved leaps and bounds over the last year. It seems perfectly feasible to me, especially for a company with AMD's resources, to adequately provide the functionality and optimizations needed to overcome the CUDA moat for AI training and inference. It is already happening.
So, while the entire CUDA ecosystem can't be replaced, the high-value, lucrative workloads can definitely be contested, as I see it.
Further reading:
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 25K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 24K
-

-
