Programming environment introduction
The AMD programming environment comes under the ROCm (Radeon Open Compute) brand. As the name suggests, it is mostly open source components, but they are actively developed and maintained by AMD, the source code is hosted at
RadeonOpenCompute/ROCm, and the documentation can be found on
ROCm documentation platform.
The ROCm software stack contains the usual set of accelerated scientific libraries, such as ROCBlas for BLAS functionality and ROCfft for FFT, etc. The AMD software stack naturally also comes with the necessary compilers needed to get code compiled for the GPUs. The AMD GPU compiler will have support for offloading through OpenMP directives. In addition, the ROCm stack comes with HIP, which is AMDs replacement for CUDA, and the tools required to make translating code from CUDA to HIP much easier. The code translated to HIP can still work on CUDA hardware. We will cover translating codes to HIP in more detail in later posts.
The ROCm stack also includes the tools needed to debug code running on the GPUs in the form of ROCgdb, AMDs ROCm source-level debugger for Linux based on the GNU Debugger (GDB). For profiling, the ROCm stack also comes with rocProf, implemented on the top of rocProfiler and rocTracer APIs, allowing you to profile code running on the GPUs. AMD provides its MIOpen library, an open-source library for high performance machine learning primitives for machine learning. MIOpen provides optimized hand-tuned implementations such as convolutions, batch normalizations, poolings, activation functions, and recurrent neural networks (RNNs).
In addition to the AMD software stack, LUMI will also come with the full Cray Programming Environment (CPE) stack. The Cray programming environment comes with the needed compilers and tools that help users port, debug, and optimize for GPUs and conventional multi-core CPUs. It also includes fine-tuned scientific libraries that can use the CPU host and the GPU accelerator when executing kernels [...].
Getting your code ready for LUMI
While LUMI does include a partition with CPU-only nodes, most of the performance comes from GPU nodes. If you want to take full advantage of LUMI, you will need to make sure your code can do at least the majority of its work on the GPUs. If your codes currently don’t utilize any GPU acceleration, now is a great time to start looking into what parts could benefit from GPU acceleration. If you are using a code that currently uses GPU acceleration, some porting may still be needed. In cases where the code is widely used in the community, and you are not the developer, the porting effort will likely be made by someone else. But in the cases where the code is something you have developed yourself, you will need to do some porting work. If the current code uses CUDA, that code will need to be converted to AMD’s equivalent to HIP. The HIP is very similar to CUDA, and there are source-to-source translation tools available that will do the majority of the conversion work, see the
Questions and Answers section below. Some OpenACC support level is available for the AMD hardware used, but it may be worth considering converting OpenACC codes to use OpenMP offloading instead. [...]
Questions and Answers
How was the LUMI vendor chosen? — The LUMI contract was awarded based on a combination of functional requirements and performance/cost metrics. The functional requirements included things like a working software stack etc. For the cost/performance metric, the performance was a combination of synthetic benchmarks such as the industry-standard HPL and HPCG benchmarks but also a set of application benchmarks. The application benchmark set consisted of three benchmarks from the MLPerf benchmarks set and 4 codes with 6 different input cases; the codes are applications that are widely used within the LUMI consortium. The non-ML part of the application benchmarks consisted of codes using either CUDA and one using OpenACC to offload their computation to the GPU. With this type of benchmark set, we enforced additional functionality requirements that there needs to be a robust way to translate or run programs using CUDA on the machine.
How will my CUDA-code work on LUMI? — Your CUDA code has to be converted to AMD HIP to work with the AMD GPUs. The HIP is a C++ Runtime API and Kernel Language that can be used to create portable applications for AMD and NVIDIA GPUs using the same source code. AMD provides various tools for porting CUDA code to HIP so that the developer does not have to port all of the code manually, we still expect some manual modifications, and performance tuning for the hardware to be needed. Code converted to HIP can also run on CUDA hardware using just the HIP header files, allowing you to maintain only the HIP version of your code. When running HIP on CUDA hardware, the performance should be similar to the original CUDA code’s performance. Many CUDA libraries are also ported or in the process of being ported. AMD provided its optimized libraries; for example, the AMD BLAS library comes in the form of rocBLAS. They also offer an additional convenience library, hipBLAS, to allow HIP programs to call the appropriate BLAS libraries based on the hardware they are running on, i.e., rocBLAS will be called on an AMD platform and cuBLAS on a CUDA platform. Recently Hipfort was also released, which is a way for Fortran codes to access the HIP libraries and allow them to offload code to AMD GPUs.
How will my OpenACC code work on LUMI? — A community effort, led by Oak Ridge National Laboratory, supports OpenACC in the GNU compilers. The most recent GCC release, currently 10.1, supports OpenACC 2.6. We expect that GCC’s support and stability will improve and be better closer to the GPU partition availability. If you can currently build your OpenACC programs with the GNU compiler, you should be able to use OpenACC on LUMI. As an alternative to OpenACC, LUMI will support programs using OpenMP directives to offload code to the GPUs. OpenMP offloading has better support from the system vendor, meaning it may be worth considering porting your OpenACC code to OpenMP.
How can I run my favourite ML framework on LUMI? — The most well-known machine learning frameworks are going to be available for AMD GPUs. For example, TensorFlow and PyTorch are already supported by AMD, and their effort continues to bring the best experience for the machine learning users. You can find more information
here.
Can other programming approaches for GPUs be used on LUMI?
OpenMP — With OpenMP, it is possible to offload computation to the GPUs using similar directives as one can use to create multithreaded applications. The AMD compiler and the Cray compiler both support offloading to the AMD GPUs used in LUMI and will support the latest version 5.0 of the OpenMP standard.
OpenCL — AMD has long been supporting OpenCL, and that support should continue. The AMD OpenCL driver supports CPUs and GPUs, and the programming environment includes debugging and profiling tools (CodeXL) and performance libraries like clMath. Documentation for OpenCL on AMD GPUs can be found at
ROCm Documentation platform.
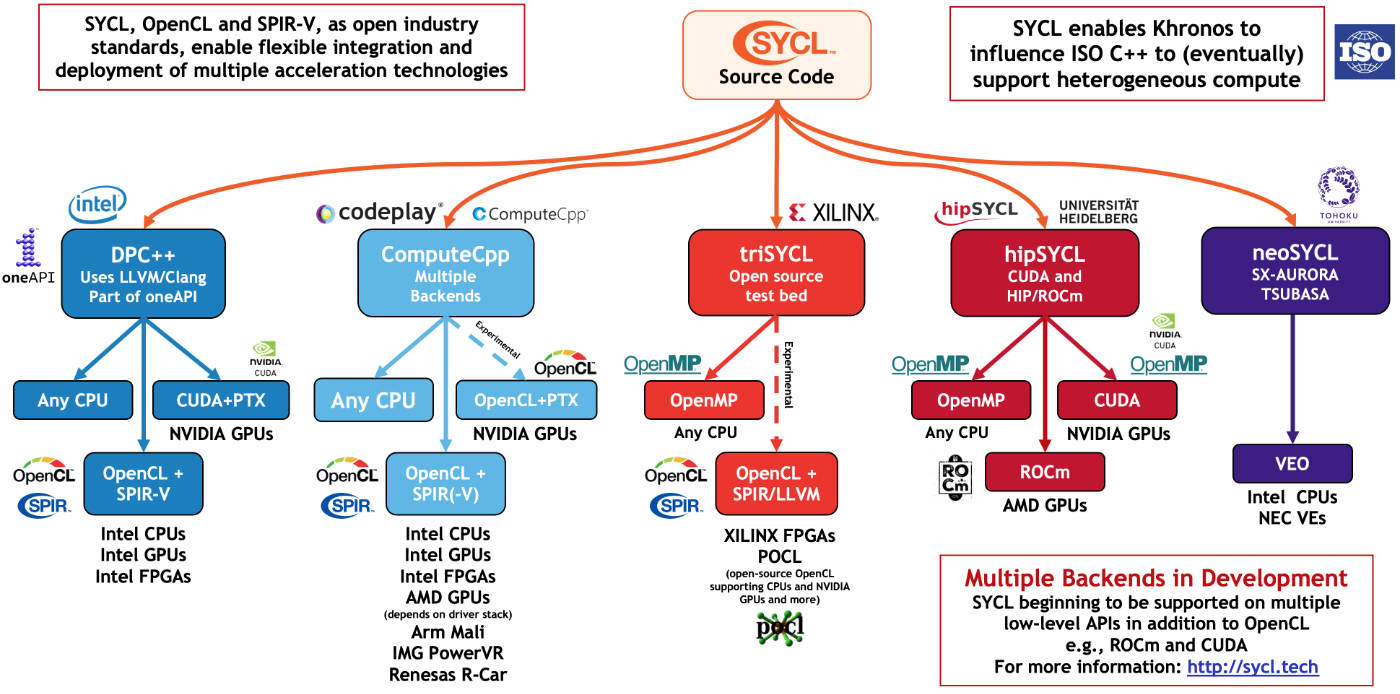
SYCL — SYCL is a single-source C++-based programming model targeting systems with heterogeneous architecture. Multiple SYCL implementations are supporting AMD GPUs. HipSYCL is an SYCL implementation built on HIP; as such, it targets both AMD and NVIDIA GPUs; another alternative is using Codeplays ComputeCpp SYCL implementation that also supports AMD GPUs.
Libraries — Many libraries offer GPU acceleration for specific operations. For instance, for linear algebra, there is the BLAS library that AMD has created their version that can offload the computation done to the GPU. Using these libraries can be an easy way to get part of your program offloaded to GPUs.