AMD Navi 31, the first desktop chiplet-based GPU? Navi 31 shaping into a true compute monster. We have heard rumors about the upcoming Navi 31 GPU for a while now. In fact, there have been rumors about Navi 41 already. The Navi 31 might be AMD’s first MCM (multi-chip module) design. NVIDIA is...

videocardz.com
AMD Navi 31, the first desktop chiplet-based GPU?
Navi 31 shaping into a true compute monster.
We have heard rumors about the upcoming Navi 31 GPU for a while now. In fact, there have been rumors about
Navi 41 already. The Navi 31 might be AMD’s first MCM (multi-chip module) design. NVIDIA is too expected to take the same route with its Hopper series, however, it remains unclear if the architecture is meant for gaming or compute workloads. On the other hand, AMD made it clear that RDNA3 has Radeon DNA and it is for sure aiming at the gaming market.
The successor to Instinct MI100 (no longer called Radeon) based on Arcturus GPU and CDNA architecture will compete with NVIDIA’s Gx100 compute chips. The CDNA is more than likely to take the same path with multi-chiplet design at some point in the future – it is simply easier to synchronize simple compute workloads across multiple dies rather than complex graphics. Even Intel’s Xe-HP architecture will be based on ’tiles’, which might be the industry’s first attempt at GPGPU chiplet design.
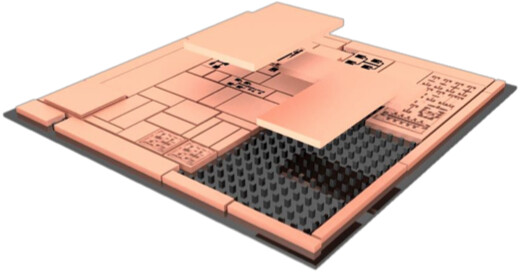
AMD Navi 31 had already appeared in a
macOS11 leak. But we have not heard much about the architecture ever since. AMD actually did talk about RDNA 3 architecture back in November, but the information provided by AMD’s EVP Rick Bergman was only related to one topic – power efficiency. In an interview with The Street back in November, Rick Bergman confirmed that AMD is committed to delivering the same performance per watt improvement over RDNA 2.
Bergman: “Let’s step back and talk about the benefits of both. So why did we target, pretty aggressively, performance per watt [improvements for] our RDNA 2 [GPUs]. And then yes, we have the same commitment on RDNA 3.”
“So [there are] actually a lot of efficiencies…if you can improve your perf-per-watt substantially. On the notebook side, that’s of course even more obvious, because you’re in a very constrained space, you can just bring more performance to that platform again without some exotic cooling solutions…We focused on that on RDNA 2. It’s a big focus on RDNA 3 as well.”
— AMD EVP, Rick Bergman, via The Street
A new rumor had appeared on January 1st. We have only noticed it because it was retweeted by 3DCenter.org. While it is impossible to confirm those revelations, I thought it might still be interesting to our readers. According to Twitter user
@Kepler_L2, it is rumored that Navi 31 has a dual chiplet design with 80 Compute Units each. This means that the GPU could offer up to 160 CUs in total, twice as many as Navi 21
AMD RDNA 3 is also expected to bring a noticeable performance upgrade in ray tracing. Based on reviews, the RDNA 2 implementation of ray tracing hardware acceleration is clearly not as good as NVIDIA 2nd Gen RT core, so AMD has a lot of work to catch up. We are still waiting for more details on AMD’s implementation of Deep Learning Super Sampling for AI-based super-resolution technology. Those, however, would be based on Tensor-like compute cores and AMD has so far not implemented such cores into their GPUs. Would Navi 31 offer such a type of core? It is unknown yet.
Patent-hunting Twitter user @Underfox3 has recently discovered that AMD has is already developing a technology to synchronize workload between MCM based GPUs and a new command processor orchestrating ray tracing pipeline for next-gen GPUs. Those two may appear in RDNA 3 architectures.
AMD has never confirmed when exactly could RDNA 3 architecture be announced, but based on the roadmaps, AMD is expected to talk about the architecture by 2022. It would appear that AMD might lift a curtain on RDNA3 somewhere later this year.