- Aug 4, 2004
- 2
- 0
- 66
I've built computers for a long time but since my college days I've only had a laptop. I started a small business and need a computer for a sole purpose.
I will be running multiple threaded python scripts which use a selenium web driver to launch roughly 30-60 Chrome profiles at once and complete a few web based tasks. It uses screen scrapped info to process some things.
It will launch 30-60 independent sessions of the website concurrently and load through 4-5 web pages. From start to finish it takes about 1 min 30 seconds to complete each session. Once the 30-60 sessions are complete it would close the windows (profiles) and launch another 30-60 until it works its way through a configuration file.
My max budget is about $6000 on this computer but i've read that AMD has a serious advantage over intel now. I realize that these new Ryzen chips are hard to come by and I will likely need to purchase one off ebay at a considerable markup. Don't love the idea but this computer is critical to my business.
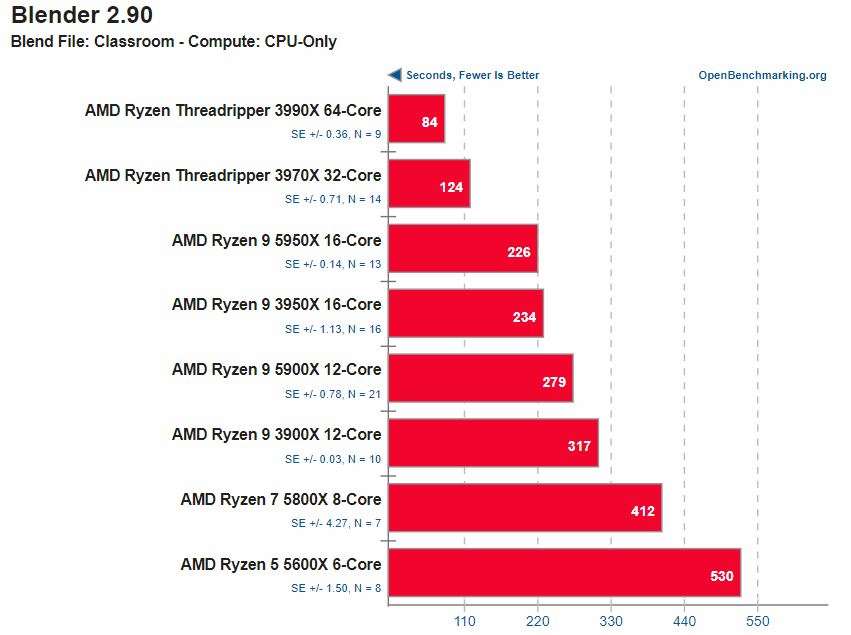
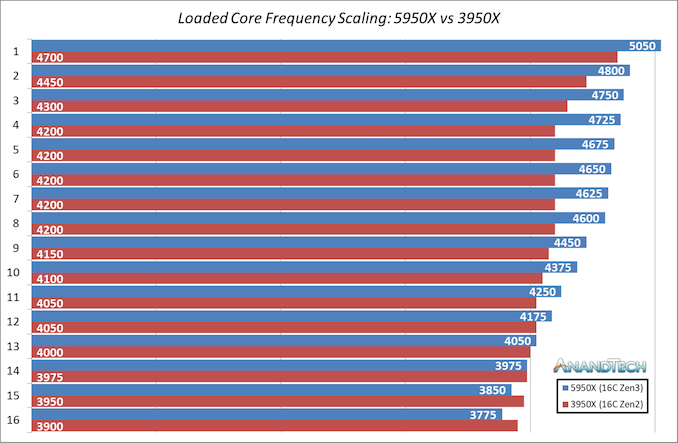
Is the 5950X worth getting over the 5900X for my purpose ? Any other thoughts and suggestions would be great. I plan on buying other high end components for the computer as well, but to get an idea of what I need to pick out. I need to start with a processor
The computer will need to run 24/7 or close too, but will be idle during alot of that time. I spend a lot of time traveling for my day job so I need to be able to remote into the computer at my house.
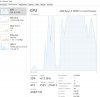
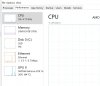
This is a friends setup. He is launching 20 profiles at once with a Ryzen 9 3900X, 64 GB Ram and a 1 TB SSD.
First picture is at idle and second is at load ( 20 profiles)
Thanks!
I will be running multiple threaded python scripts which use a selenium web driver to launch roughly 30-60 Chrome profiles at once and complete a few web based tasks. It uses screen scrapped info to process some things.
It will launch 30-60 independent sessions of the website concurrently and load through 4-5 web pages. From start to finish it takes about 1 min 30 seconds to complete each session. Once the 30-60 sessions are complete it would close the windows (profiles) and launch another 30-60 until it works its way through a configuration file.
My max budget is about $6000 on this computer but i've read that AMD has a serious advantage over intel now. I realize that these new Ryzen chips are hard to come by and I will likely need to purchase one off ebay at a considerable markup. Don't love the idea but this computer is critical to my business.
Is the 5950X worth getting over the 5900X for my purpose ? Any other thoughts and suggestions would be great. I plan on buying other high end components for the computer as well, but to get an idea of what I need to pick out. I need to start with a processor
The computer will need to run 24/7 or close too, but will be idle during alot of that time. I spend a lot of time traveling for my day job so I need to be able to remote into the computer at my house.
This is a friends setup. He is launching 20 profiles at once with a Ryzen 9 3900X, 64 GB Ram and a 1 TB SSD.
First picture is at idle and second is at load ( 20 profiles)
Thanks!