A little strange he used m instances versus the Rome c instance, but the c instance is the only Rome one available at this point. M instances give double the memory but are also more expensive.
He simply had the results from the last time (remember the Rome instances had only been up only for a few hours).
Overal Rome is quite strong, considering that half of it's cores are SMT. It is slightly dissapointing that Amazon decided to not pass the savings on to the customer and only offers a 10% discount vs Intel servers. Though realistically it should be closer to 50% (according to servethehmoe VM comparison):
He simply had the results from the last time (remember the Rome instances had only been up only for a few hours).
Overal Rome is quite strong, considering that half of it's cores are SMT. It is slightly dissapointing that Amazon decided to not pass the savings on to the customer and only offers a 10% discount vs Intel servers. Though realistically it should be closer to 50% (according to servethehmoe VM comparison):
1) Why would Amazon decide to "pass the savings on to the customer"?!
2) Seriously, where did you get that 50% from? It's definitely not in the STH article.
1) Why would Amazon decide to "pass the savings on to the customer"?!
2) Seriously, where did you get that 50% from? It's definitely not in the STH article.
1) Why not? They have done so in the past to gain competitive advantage. Or should virtual servers cost the same as say in 2008 (per core and gb and hdd size), just because "why whould they?"
2) I said closer not at 50% but I agree this might be a stretch. But because:
Twitter confirmed 30% TCO savings from using EPYC (on that link 40% more cores same power, but previously they mentioned TCO as well).
Because already Epyc Napels was 10% cheaper on Amazon and Rome has twice the cores in the same TDP
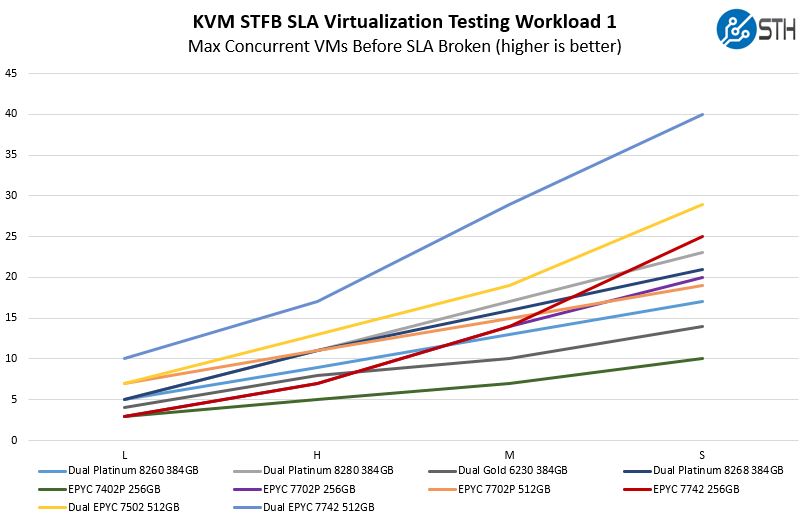
As for the servethehome article. Did you miss the chart?
2x EPYC 7742 can run 40 small VMs within SLA (bigger VMs have similar ratio)
I am sure they are also wanting to make sure their ARM instances continue to look cost/performance competitive. Since they have their own in house platform, I think that perspective always has to be considered in AWS cost and configurations.
1) Why not? They have done so in the past to gain competitive advantage. Or should virtual servers cost the same as say in 2008 (per core and gb and hdd size), just because "why whould they?"
But what would they gain by launching even cheaper VMs?
They decided to use EPYC, they ordered custom chips, they set it up.
They already are the dominant player on this market. And now they'll make money.
And if Azure or GCP launch cheaper VMs and start to steal some clients, AWS will have headroom to react.
Why do it now? It makes absolutely no sense.
2) I said closer not at 50% but I agree this might be a stretch.
No offense, but do you understand this test?
Because these results don't mean that AWS needs two 8260 to offer VMs with 17 cores total.
We don't even know what kind of VMs are being run. It's an internal test from an undisclosed company with pretty much zero value to a reader. (I don't know why STH included it)
FYI I'm a full-stack web software engineer. I've been in the industry for 13 years and for the last 8 I've developed mostly cloud-based software and apps. I've co-developed and deployed dozens of projects and hundreds of different microservices to multiple public and at last one private cloud (AWS, DigitalOcean, Azure being the most common on the public side). Clients include Banking and Telco companies (so not exactly small-scale).
BTW Just last week I deployed to staging an MVP of a new project. A docerized SPA deployed to Amazon (Backend is a bit archaic, but it's what the client wanted: Spring Boot Backend with a Node.js Server-side-rendering node with React.js frontend, static assets being served via Cloudfront CDN). The app is published to Amazon ECR and deployed to EC2 instances.
For my masters degree I worked with GPGPU computing (including some metrology code that ran on Titan Supercomputer, in 2012) and I like hacking away at some close-to-metal hobby projects (in Rust) if I have time. So I'm at least aware of the vastly different bottlenecks in such projects vs web/app stuff.
TL;DR: I have some "limited" experience know what "a VM" is and don't think the graph about 17 VMs is 100% extrapolatable to Amazon.
As I said EPYC Naples was already 10% cheaper than Skylake-X. What you are claiming is that Rome offers single digit gains with double the core-density per rack at similar power with double the I/O (PCIe 4) vs Napels. That's absurd.
Obviously power-draw in itself is not the issue. But It is relevant percisely in what it entails:
Power generates heat, heat neets to be cooled off. And what is the main limiting factor of socket/rack density for current designs? It's cooling capacity (and based on your posts you're well aware of that) If cooling wasn't an issue you'd see Intel's 450-400W 9200 series or Cooper Lakes sell much better than they are.
You need to cool every extra W you put in a rack, and that adds up quickly. I would love for @Markfw to chime in about the relevance of powerdraw and what it does to the final bill (with cooling and everyhing included) his experience, as he has actually deployed/operated servers.
Yet they operate a web-service that is quite similar to what many of AWS users do. It's not an exact comparison but that doesn't render all their data useless.
Besides Twitter Is by no means the only one citing large performance gains. L1Techs Wendell (who is doing different server racks to all kinds of people) has mentioned in multiple videos that you can replace 2 Broadwell (or older) dual-socket servers with a single socket Rome server. Or you can replace a dual-socket Skylake-X with a single socket Rome server. For actual clients and actual workflows.
There are several other example, Take Cloudflare for instance (Yes, CDN workloads are a bit different, but far from irrelevant. These would perfectly match amazon's Cloudfront needs, and many S3 workflows as well. The cache locality and RPS charts are quite relevant in many places).
There are plenty more but these are the first things that jumped to mind.
Because these results don't mean that AWS needs two 8260 to offer VMs with 17 cores total.
We don't even know what kind of VMs are being run. It's an internal test from an undisclosed company with pretty much zero value to a reader. (I don't know why STH included it)
Obviously the milage will vary depending on the code actually run in those VMs (btw there are 4 different VMs on that chart all showing simialar scaling). It's far from ideal but it's way more useful than canned tests, e.g. in Phoronix test-suite. And it's yet another client having a similar speedup when running on Rome than all the other I mentioned
Which brings me to the point:
A lot of different companies with all kinds of varied workloads are all seeing they can replace 2-socket Skylake with 1-socket Rome and get some performance boost to boot.
Why on earth would Amazon with it's general-purpose VM's will somehow be an exception?
What exactly in Rome's platform would inhibit it from reaching said benefits, after they have been demonstrated by multiple other customers?
Only 33% more memory-bandwidth? (actually a bit more since it supports 3200 Mhz ECC RAM), a Lack of AVX-512? (If you have a heavy vector workload and you're running it on Amazon general-purpose VMs you are a moron of unspeakable dimentions).
Bear in mind that every workflow that's not stressing either Network, IO CPU or Memory will automatically scale 2x compared to Skylake (as there are 2x the cores you can sell to clients). CPU bound scenarios are covered (2x the cores all-core clocks competitive to 28-core competition), as are network and disk related (due to very low limits set by amazon on non-specialized instances).
What Arcane software must these EC2 instances be running to get "12%" improvement?
FYI I'm a full-stack web software engineer. I've been in the industry for 13 years and for the last 8 I've developed mostly cloud-based software and apps. I've co-developed and deployed dozens of projects and hundreds of different microservices to multiple public and at last one private cloud (AWS, DigitalOcean, Azure being the most common on the public side). Clients include Banking and Telco companies (so not exactly small-scale).
BTW Just last week I deployed to staging an MVP of a new project. A docerized SPA deployed to Amazon (Backend is a bit archaic, but it's what the client wanted: Spring Boot Backend with a Node.js Server-side-rendering node with React.js frontend, static assets being served via Cloudfront CDN). The app is published to Amazon ECR and deployed to EC2 instances.
For my masters degree I worked with GPGPU computing (including some metrology code that ran on Titan Supercomputer, in 2012) and I like hacking away at some close-to-metal hobby projects (in Rust) if I have time. So I'm at least aware of the vastly different bottlenecks in such projects vs web/app stuff.
TL;DR: I have some "limited" experience know what "a VM" is and don't think the graph about 17 VMs is 100% extrapolatable to Amazon.
Now to the matter at hand:
As I said EPYC Naples was already 10% cheaper than Skylake-X. What you are claiming is that Rome offers single digit gains with double the core-density per rack at similar power with double the I/O (PCIe 4) vs Napels. That's absurd.
Obviously power-draw in itself is not the issue. But It is relevant percisely in what it entails:
Power generates heat, heat neets to be cooled off. And what is the main limiting factor of socket/rack density for current designs? It's cooling capacity (and based on your posts you're well aware of that) If cooling wasn't an issue you'd see Intel's 450-400W 9200 series or Cooper Lakes sell much better than they are.
You need to cool every extra W you put in a rack, and that adds up quickly. I would love for @Markfw to chime in about the relevance of powerdraw and what it does to the final bill (with cooling and everyhing included) his experience, as he has actually deployed/operated servers.
Yet they operate a web-service that is quite similar to what many of AWS users do. It's not an exact comparison but that doesn't render all their data useless.
Besides Twitter Is by no means the only one citing large performance gains. L1Techs Wendell (who is doing different server racks to all kinds of people) has mentioned in multiple videos that you can replace 2 Broadwell (or older) dual-socket servers with a single socket Rome server. Or you can replace a dual-socket Skylake-X with a single socket Rome server. For actual clients and actual workflows.
There are several other example, Take Cloudflare for instance (Yes, CDN workloads are a bit different, but far from irrelevant. These would perfectly match amazon's Cloudfront needs, and many S3 workflows as well. The cache locality and RPS charts are quite relevant in many places).
There are plenty more but these are the first things that jumped to mind.
Obviously the milage will vary depending on the code actually run in those VMs (btw there are 4 different VMs on that chart all showing simialar scaling). It's far from ideal but it's way more useful than canned tests, e.g. in Phoronix test-suite. And it's yet another client having a similar speedup when running on Rome than all the other I mentioned
Which brings me to the point:
A lot of different companies with all kinds of varied workloads are all seeing they can replace 2-socket Skylake with 1-socket Rome and get some performance boost to boot.
Why on earth would Amazon with it's general-purpose VM's will somehow be an exception?
What exactly in Rome's platform would inhibit it from reaching said benefits, after they have been demonstrated by multiple other customers?
Only 33% more memory-bandwidth? (actually a bit more since it supports 3200 Mhz ECC RAM), a Lack of AVX-512? (If you have a heavy vector workload and you're running it on Amazon general-purpose VMs you are a moron of unspeakable dimentions).
Bear in mind that every workflow that's not stressing either Network, IO CPU or Memory will automatically scale 2x compared to Skylake (as there are 2x the cores you can sell to clients). CPU bound scenarios are covered (2x the cores all-core clocks competitive to 28-core competition), as are network and disk related (due to very low limits set by amazon on non-specialized instances).
What Arcane software must these EC2 instances be running to get "12%" improvement?
Thanks for the credit @Gideon , but @StefanR5R has more Intel dual socket servers and better power stats than I do.
Stefan, can you respond to this thread with your takes on all this ? Especially the power savings of Rome vs Xeons.
I know that from What I read, for the same "power of processing", The Rome used half the power (from what I saw). Lets wait until Stefan replies before we discuss this further. Oh, and from a data center perspective, the 1/2 power relates to 1/4th the electric bill due to AC in a data center. Thats real savings, as the power bill in data centers is not small, I know that from when I used to work for a very large company with square miles of data center floor, as well, as my own electric bill.
Edit: One final note, here are the EPYC servers and Xeon servers I have at the house:
Xeon
2 systems, each with E5-2683v3 CPUs (14 core 28 thread), I used to have 6 of them.
I am not positive, becuase I don;t have the kill-a-watt on them right now, but I think I am getting the same power usage (about) on an EPYC 7452 32 core as my Xeon 14 core, but about 3 times the processing power. The EPYC runs at 2.6 ghz, and the Xeon at 2.5 GHZ
This site uses cookies to help personalise content, tailor your experience and to keep you logged in if you register.
By continuing to use this site, you are consenting to our use of cookies.