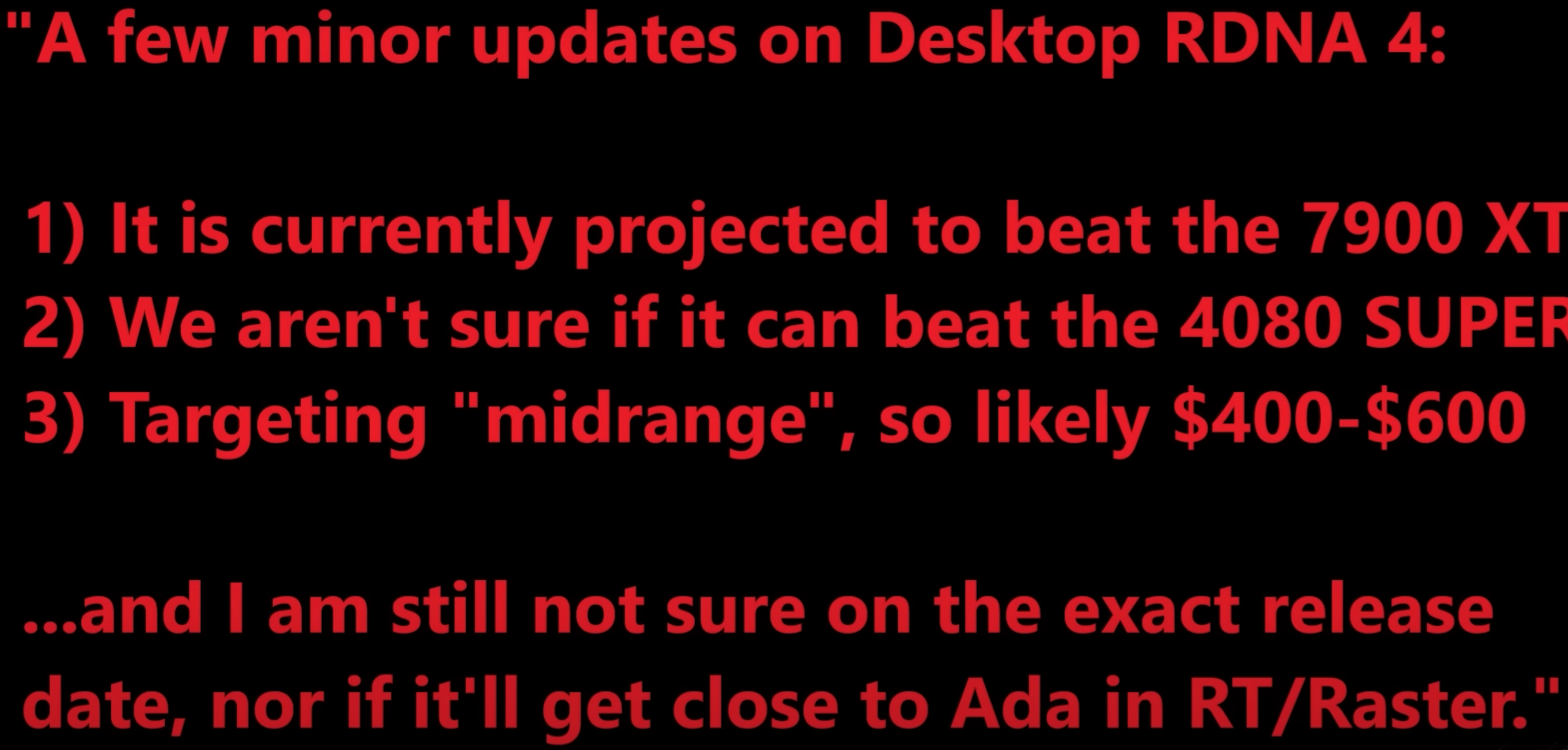
DisEnchantment
Golden Member



With the GFX940 patches in full swing since first week of March, it is looking like MI300 is not far in the distant future!
Usually AMD takes around 3Qs to get the support in LLVM and amdgpu. Lately, since RDNA2 the window they push to add support for new devices is much reduced to prevent leaks.
But looking at the flurry of code in LLVM, it is a lot of commits. Maybe because US Govt is starting to prepare the SW environment for El Capitan (Maybe to avoid slow bring up situation like Frontier for example)
See here for the GFX940 specific commits
History for llvm/lib/Target/AMDGPU - llvm/llvm-project
The LLVM Project is a collection of modular and reusable compiler and toolchain technologies. - History for llvm/lib/Target/AMDGPU - llvm/llvm-project
 github.com
github.com
More AMD "GFX940" Enablement Work Landing In LLVM - Phoronix
 www.phoronix.com
www.phoronix.com
There is a lot more if you know whom to follow in LLVM review chains (before getting merged to github), but I am not going to link AMD employees.
I am starting to think MI300 will launch around the same time like Hopper probably only a couple of months later!
Although I believe Hopper had problems not having a host CPU capable of doing PCIe 5 in the very near future therefore it might have gotten pushed back a bit until SPR and Genoa arrives later in 2022.
If PVC slips again I believe MI300 could launch before it

This is nuts, MI100/200/300 cadence is impressive.

Previous thread on CDNA2 and RDNA3 here
Question - Speculation: RDNA3 + CDNA2 Architectures Thread
Man I have been dying to make this one for a while now. First rumours for RDNA3 are here so new thread time! Just going to start off with this one for now: kopite7kimi on Twitter: "@VideoCardz Ah, I mean a simple mcm design with 10240 cores is not enough. Because the lift from RDNA2 to RDNA3...
Last edited: