Thanks! just finished it up. Epic, epic spreadsheet.

Affinity Set 0,1
2 Threads: 21.0649
0,1,2
3 Threads: 30.6025
Updated i7 920 info added to my previous google doc.
I used problem size 16134, HT off and locked the threads to 1 core each. 5 passes each test.
I've run it with varying thread counts, but with a fixed problem size of 15000. LinX assigned 1729MB of memory.
CPU: Phenom II 955 BE
Core Frequency: 3600 MHz
NB/Uncore Frequency: 2250 MHz
Memory Frequency: DDR2-900 (5-5-5-15)
Thread Count : GFlops
1 : 12.24 GFlops
2 : 23.96 GFlops
3 : 35.20 GFlops
4 : 45.73 GFlops
http://cid-17de86f1059defe0.skydriv...inpack Challenge/Perf^_per^_Thread^_955BE.jpg
(898MHz reported by cpu-z is due to C'nQ)
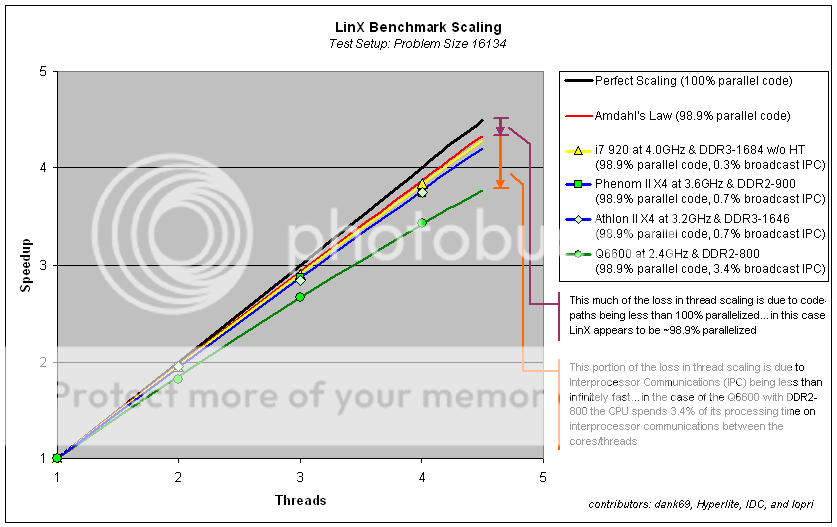
Gentlemen, I present you with our grand thread scaling overlay:
Thanks to all your data I was all the better able to zero-in on a proper estimate of the parallel code percentage present in the LinX computations, coming in at around 98.9% (revised upwards).
Interestingly we see that the L3$ on Phenom II X4 does not appear to improve the thread scaling in this benchmark versus that of the Athlon II X4. While this is not surprising at first glance given that we are intentionally operating on matrix sizes that force the usage of paging to the ram on the other side of the memory controller it is interesting to see that the pre-fetch mechanisms in play for the L3$ on Phenom II do not yield an advantage in thread scaling per say (but it may in terms of absolute performance on an IPC/thread metric).
Lopri is there any chance we could convince you to reduce your clockspeed to 3.2GHz to match Hyperlite's Athlon II clockspeed and rerun the 1-4 threads?
dank69 I noticed in your spreadsheet you ran both cases for 1-thread (affinity locked to one core versus no core locking) and the result was virtually identical. I noticed this too on my Kentsfield. It seems the Athlon II performance gets hit hard by thread migration in this application whereas thread migration on the Intel architectures and the PhenomII are less sensitive (completely insensitive actually).
Also we see that the IMC makes all the difference, clear delineation between the Nehalem/Deneb versus Kentsfield there. The nehalem architecture does result in about 1/2 the interprocessor communication time in comparison to the Deneb architecture (or rather its IMC intricacies).
Presumably this performance difference is stemming from the added bandwidth of the triple-channel IMC on bloomfield. If one was curious to test this theory we would repeat the 1-4 thread test but remove the ram sticks from the third channel to intentionally reduce the bandwidth (and could do it yet again to reduce the bandwidth even further to single-channel).
Thanks guys for all your time and efforts in generating this data. Pretty cool results from a geeky computer-science perspective