-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Jim Keller leaves AMD
Page 16 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
- Status
- Not open for further replies.
AtenRa
Lifer
Now that i had some time to look over it,
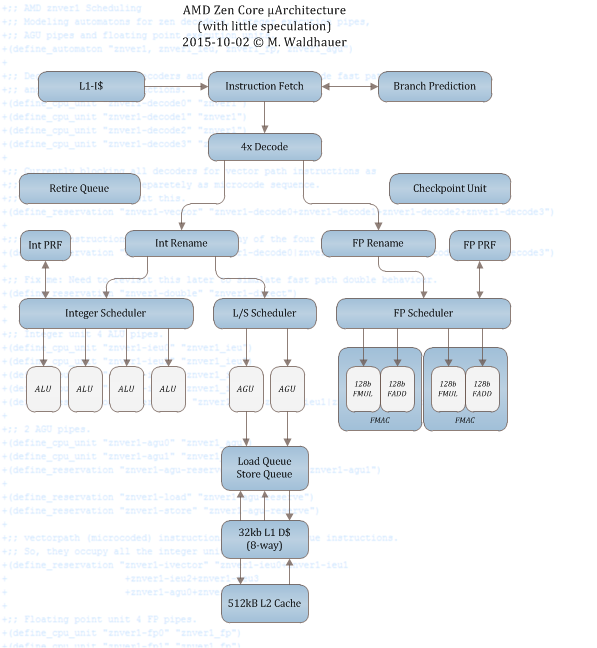
Would you say that single ZEN core will have more Integer throughput vs Excavator Module because of the lower latency and faster caches/memory + higher IPC and no CMT penalty although it has 2x less AGUs ??
Excavator Module
8x Integer Pipes / 4x ALUs and 4x AGUs
ZEN core
6x Integer pipes / 4x ALUs and 2x AGUs
Would you say that single ZEN core will have more Integer throughput vs Excavator Module because of the lower latency and faster caches/memory + higher IPC and no CMT penalty although it has 2x less AGUs ??
Excavator Module
8x Integer Pipes / 4x ALUs and 4x AGUs
ZEN core
6x Integer pipes / 4x ALUs and 2x AGUs
muziqaz
Junior Member
Now that i had some time to look over it,
Would you say that single ZEN core will have more Integer throughput vs Excavator Module because of the lower latency and faster caches/memory + higher IPC and no CMT penalty although it has 2x less AGUs ??
Excavator Module
8x Integer Pipes / 4x ALUs and 4x AGUs
ZEN core
6x Integer pipes / 4x ALUs and 2x AGUs
How much of the latency reduction need to be done in order to compensate 2 AGUs?
And we need to remember, that Zen needs to compete with Skylake and beyond, not with Excavator.
P.S. Haha, nearly 10 years ago registered, 1st post today...
CHADBOGA
Platinum Member
How much of the latency reduction need to be done in order to compensate 2 AGUs?
And we need to remember, that Zen needs to compete with Skylake and beyond, not with Excavator.
P.S. Haha, nearly 10 years ago registered, 1st post today...
Have you been driven out of
Yep. I've planned to provide more stuff over the next days. Just wanted to get that out first after discovering the patch 2 days ago. Now I need some sleep (3am here). 😉
Sweet.
And in anticipation of a possible response from the bi-curious ISA crowd, would it be possible to cajole you into including an A9 microarchitecture comparison within said table/matrix comparison? 😉 😛
(personal note, I self-identify with the bi-curious ISA contingent, call me twistlyn 😉)
itsmydamnation
Diamond Member
How much of the latency reduction need to be done in order to compensate 2 AGUs?
And we need to remember, that Zen needs to compete with Skylake and beyond, not with Excavator.
P.S. Haha, nearly 10 years ago registered, 1st post today...
The AGU's needed ALU's for some of their functions in BD, so its not that simple. Intel only has 2 address gen units in their HT cores as well so its unlikely address gen was ever a bottleneck in BD (ignoring its crazy pairing with an execution pipe).
Im interested to see how wide each core is Dresdenboy seems to think 128bit SIMD units so each core in Zen isn't any wider then a core (1/2 a module) in BD and thus 1/2 the width of haswell and co.
So bulldozer relative position was SIMD heavy(throughput, 2x FMA 2x int SIMD) and in comparison it looks like Zen is int heavy and low latency. Given that intel is going 512avx in Servers this looks like the right bet at this stage, no point going 256bit, for the workloads where you can make use of 256bit vectors over 128bit vectors i imaging that they will be prime candidates for 512bit vectors. So by staying with 128bit units keeping your cores smaller, focusing on int performance and having more cores, at least there are some pretty big points of differentiation.
Staying 128bit i guess will help the core to keep power down when targeting those ~15WATT TDP APU's. Guess we will just have to wait and see how it plays out.
Now that i had some time to look over it,
Would you say that single ZEN core will have more Integer throughput vs Excavator Module because of the lower latency and faster caches/memory + higher IPC and no CMT penalty although it has 2x less AGUs ??
Excavator Module
8x Integer Pipes / 4x ALUs and 4x AGUs
ZEN core
6x Integer pipes / 4x ALUs and 2x AGUs
Don't forget diminishing returns. Scaling beyond 2 (or three, depending on the core design and baseline point) ALUs decreases dramatically, even with things like HT, look at haswell for instance.
muziqaz
Junior Member
Have you been driven out ofAMDZone2Semi-Accurate's forums by Internet STRONGMAN Juanrga?
I have him on ignore list, so I am still there 😀
I am sceptical... nothing is too perfect than Intel (according to Shintai), and even if that is true, we need to see at what max GHZ can run it.
Internet STRONGMEN arent only found in S/A it seems.
Zen is shaping up decently, the ALU/AGU balance can be worrying in HPC according to Kanter, lets hope it doesnt become a problem in client workloads.
Margins and there is the risk that Intel can screw Apple somehow due their ARM chips.Apple designing hardware after they started purchasing Intel and discrete graphic cards? The market is too volatile for them to risk that kind of money. I think they are perfectly happy purchasing hardware tried and proven on the market as demand is needed.
DrMrLordX
Lifer
Look at the executional resources on that thing! Zen got back(end).
Looking at the projected FMAC design, I have to wonder: is Zen going to struggle with 256-bit SIMD instructions the same way that PD/SR/XV do some of the time? For those processors, 256-bit SIMD instructions (AVX, AVX2 for XV) have to be split into two 128-bit instructions before they can be used. When all else fails, that can be done in hardware, albeit at a performance penalty.
Yeah, Intel had to do a lot of work with branch prediction to avoid cache misses and the ensuing pipeline stalls that plagued Netburst. Netburst had a very long pipeline. Prescott was something like 30 or 31 stages.
So you better believe Intel incorporated those improvements into Conroe. They also stole the Netburst quad-pumped FSB.
ahhh do not say that name! They will find us!
It is too late! We are doomed.
Looking at the projected FMAC design, I have to wonder: is Zen going to struggle with 256-bit SIMD instructions the same way that PD/SR/XV do some of the time? For those processors, 256-bit SIMD instructions (AVX, AVX2 for XV) have to be split into two 128-bit instructions before they can be used. When all else fails, that can be done in hardware, albeit at a performance penalty.
"Some patents suggest, that Zen might use some slightly modified Excavator branch prediction."
If my memory serves, I recall that K8 and the Phenoms were often said to have poor branch prediction. And bulldozer was supposed to completely revamp the branch prediction.
I also seem to remember that Intel worked a lot on this with Pentium 4, and it added its work back into the P3 architecture and that became Conroe. Is this true?
It wasn't just branch prediction, though, that Conroe took from P4. But I can't remember the rest.
Yeah, Intel had to do a lot of work with branch prediction to avoid cache misses and the ensuing pipeline stalls that plagued Netburst. Netburst had a very long pipeline. Prescott was something like 30 or 31 stages.
So you better believe Intel incorporated those improvements into Conroe. They also stole the Netburst quad-pumped FSB.
Have you been driven out ofAMDZone2Semi-Accurate's forums by Internet STRONGMAN Juanrga?
ahhh do not say that name! They will find us!
Internet STRONGMEN arent only found in S/A it seems.
It is too late! We are doomed.
itsmydamnation
Diamond Member
Look at the executional resources on that thing! Zen got back(end).
Looking at the projected FMAC design, I have to wonder: is Zen going to struggle with 256-bit SIMD instructions the same way that PD/SR/XV do some of the time? For those processors, 256-bit SIMD instructions (AVX, AVX2 for XV) have to be split into two 128-bit instructions before they can be used. When all else fails, that can be done in hardware, albeit at a performance penalty.
They don't struggle they do it over two cycles, what it means is assuming you have code that can execute a 256bit vector every cycle it would have 1/2 the throughput per core of a haswell> core. The performance penalty for this(fast double) is tiny as its just another mop its the throughput that's hurt. But if you have sequential dependent instructions ZEN should be better because of the reduced instruction latency.
I dont know why people are fixated on HPC, the bread and butter of the server world is 2socket /16dimm 1ru pizza/blades running KVM/hyperV/ESXi. Now if a SOC is 16 cores and AMD MCM so 64cores a 2P server and it can maintain a reasonable clock rate (mid 2ghz) then it looks like they should have a pretty good offering in that space which is the bulk of servers.
for comparison intel 18core 150TDP is 2.3ghz base.
DrMrLordX
Lifer
They don't struggle they do it over two cycles, what it means is assuming you have code that can execute a 256bit vector every cycle it would have 1/2 the throughput per core of a haswell> core. The performance penalty for this(fast double) is tiny as its just another mop its the throughput that's hurt. But if you have sequential dependent instructions ZEN should be better because of the reduced instruction latency.
I see what you're saying, but it still still stinks when XV (for example) runs stuff like y-cruncher faster with SSE3 than it does AVX (for example). There are circumstances where Zen is going to run into AVX2 code aimed at Intel chips, and it would be nice if Zen could handle those instructions without suffering a loss of throughput. XV can't do that.
itsmydamnation
Diamond Member
I see what you're saying, but it still still stinks when XV (for example) runs stuff like y-cruncher faster with SSE3 than it does AVX (for example). There are circumstances where Zen is going to run into AVX2 code aimed at Intel chips, and it would be nice if Zen could handle those instructions without suffering a loss of throughput. XV can't do that.
the throughput of 1x256bit AVX to 2x128bit AVX should be almost identical and it was in bulldozer, but it appears over time AMD have sacrificed 256bit AVX performance as they stopped targeting servers with BD.
agner has a few notes on it from his testing
http://www.agner.org/optimize/blog/read.php?i=285
William Gaatjes
Lifer
Ok, I give up..
AMD's Zen core (family 17h) to have ten pipelines per core http://dresdenboy.blogspot.com/
Andreas Stiller, i loved reading his articles in c't magazine.
ShintaiDK
Lifer
https://benchlife.info/amd-ex-cpu-master-jim-keller-join-tesla-for-autopilot-hardware-01292016/
After speculation, Jim Keller ended up with Tesla as a VP for autopilot development.
After speculation, Jim Keller ended up with Tesla as a VP for autopilot development.
Arachnotronic
Lifer
https://benchlife.info/amd-ex-cpu-master-jim-keller-join-tesla-for-autopilot-hardware-01292016/
After speculation, Jim Keller ended up with Tesla as a VP for autopilot development.
Looks like AMD soured this dude on chips altogether 😛
SlowSpyder
Lifer
Good for Jim. Tesla seems to be the new and exciting Frontier.
He's used to working for companies that don't turn a profit, it would appear. 😛
Dresdenboy
Golden Member
A postponement of K12 could have caused that. One wants to do something new and would still have to wait longer than anticipated with finishing the current project..Looks like AMD soured this dude on chips altogether 😛
And Fottemberg was right about Keller "retiring" (from chip design).
NTMBK
Lifer
Looks like AMD soured this dude on chips altogether 😛
Nah, clearly Superman Keller will design an entire new world-class CPU architecture to drive Tesla's AI :awe:
- Status
- Not open for further replies.
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 25K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 24K
-

-
