ShintaiDK
Lifer
http://www.nextplatform.com/2016/06/20/intel-knights-landing-yields-big-bang-buck-jump/
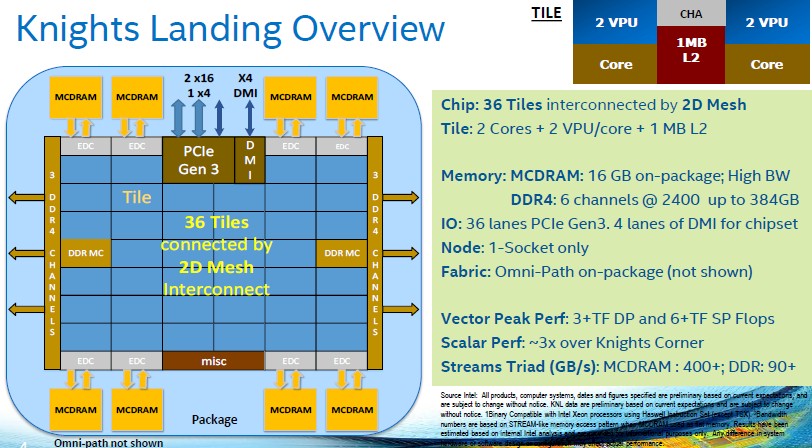

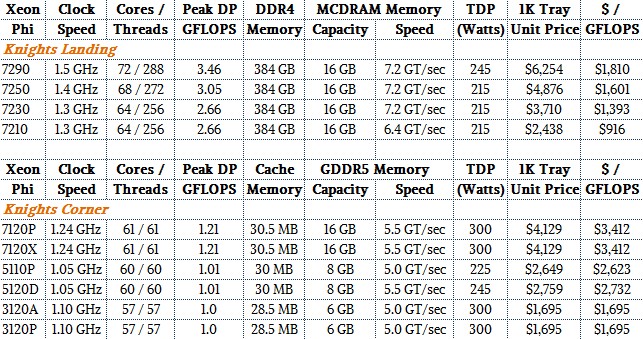


Wuischpard said that Intel expects to ship more than 100,000 Xeon Phi units this year into the HPC market, and there is a good chance that more than a few hyperscalers are going to buy a bunch, too, for machine learning and possibly other workloads. More than 30 software vendors have ported their code to the new chip, and others will no doubt follow. And more than 30 system makers are bending metal around the Knights Landing processors.
We also hear that Intel may do something special with Knights Landing for the machine learning crowd from a keynote address at the ISC 2016 conference today, so stay tuned for that.
The single-socket Knights Landing processor is compatible with both the Linux and Windows Server operating systems that dominate datacenters today, and indeed any application that has been certified to run on either can run on a Knights Landing. That opens up the market for them pretty wide, too.
Now we find out how customers will use it.