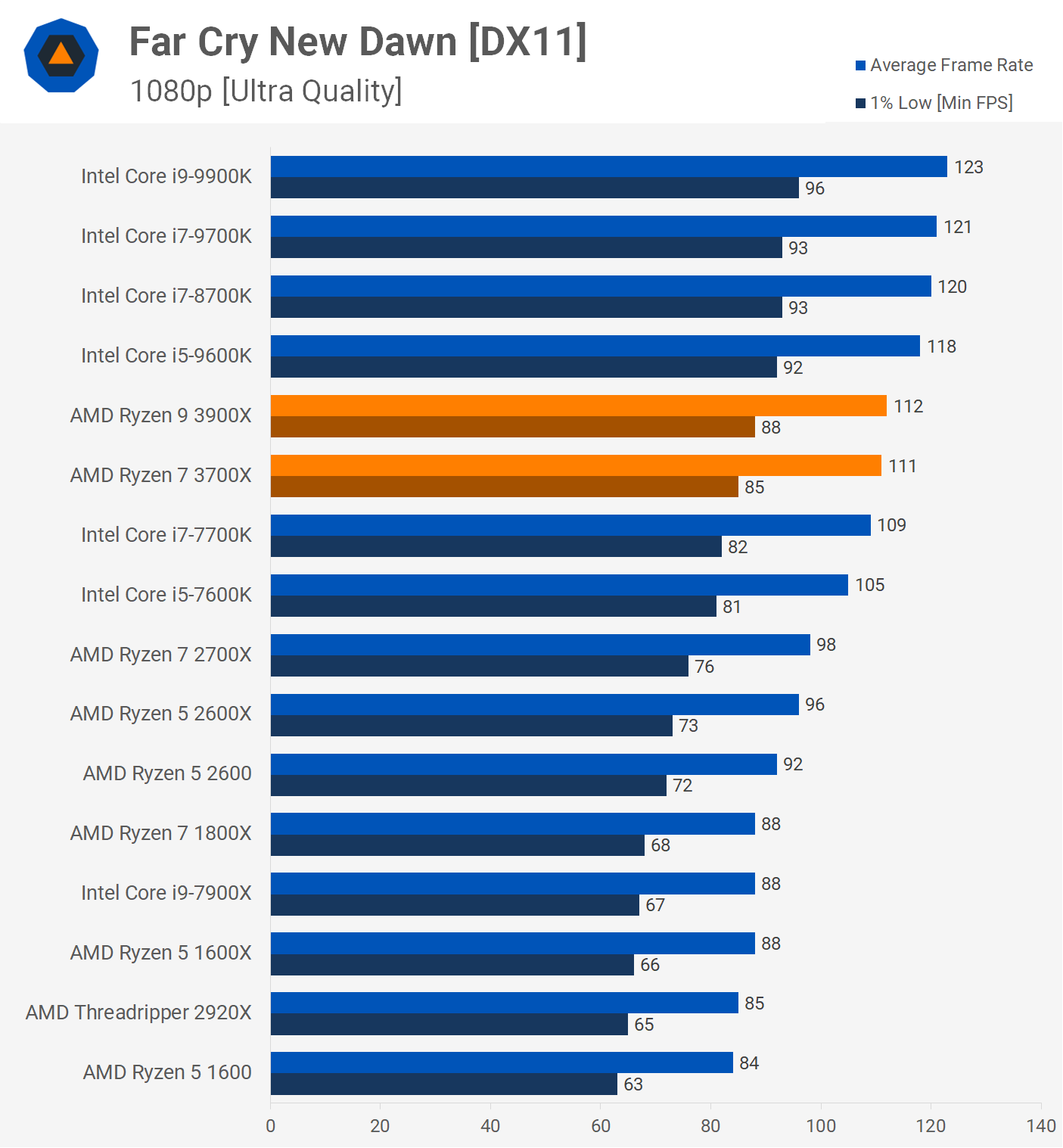
If we could get both companies to design a CPU core now on the same process and using the same number of transistors, who would be ahead and by how much? I'm assuming Intel would be ahead because Skylake has a similar IPC to Zen 2, but Zen 2 uses a more dense node, and Skylake is from 2015 while Zen 2 is from 2019.
The both companies using the same process scenario is just to illustrate the problem and I know it will never happen, but maybe there is a smart way to compare current CPU designs and find out who is ahead and by how much. Wikichip has die sizes and die pictures of Sunny Cove and Zen 2, but I'm not sure how to interpret and compare them.
Another question: If Intel had to design future cores using the same process and the same die size as Skylake, how much further could the Skylake design be improved? Also assuming it will have to have to be x86 too and have all the same functions.
The both companies using the same process scenario is just to illustrate the problem and I know it will never happen, but maybe there is a smart way to compare current CPU designs and find out who is ahead and by how much. Wikichip has die sizes and die pictures of Sunny Cove and Zen 2, but I'm not sure how to interpret and compare them.
Another question: If Intel had to design future cores using the same process and the same die size as Skylake, how much further could the Skylake design be improved? Also assuming it will have to have to be x86 too and have all the same functions.