-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
computerbaseAshes of the Singularity Beta1 DirectX 12 Benchmarks
Page 23 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
airfathaaaaa
Senior member
because this was the problem all along with nvidia they are offloading gpu resources to the cpu this was that everyone knew its was going to happen on dx12/mantle/vulkanBecause their DX11 is worse than nVidia's and nVidia's architecture isnt geometry bound like AMDs.
"quality sources"? You mean this insider guy from oxide? Haha.
If you think nVidia wont benefit from multi thread rendering then explain why this demo (Vulkan Threaded Rendering) scales over all 8 threads of my CPU:
https://developer.nvidia.com/vulkan-android#samples
this is what happened on aos too they hammered the cpu with additional workload while the cpu was already doing the normal graphic workload..
Yes, and with Async Compute you can send BOTH Graphics AND Compute AND Copy to the GPU at the same time. When without Async Compute you will only send one of them at the time.
You can send as many queues as you want to a GPU at the same time.
:\But you need lots of CPU Threads in order to do that. That is why you will not get that much benefit from Multi-Core CPUs (Multi-Rendering) on MAXWELL. Because at the end of the day the GPU will only render one job at a time, either Graphics OR Compute OR Copy.
Sorry, but you should read more about the API and GPUs. GPUs doing more than just "one job at a time". They need thousends of threads to hide the latency.
because this was the problem all along with nvidia they are offloading gpu resources to the cpu this was that everyone knew its was going to happen on dx12/mantle/vulkan
this is what happened on aos too they hammered the cpu with additional workload while the cpu was already doing the normal graphic workload..
They dont offloading anything.
Last edited:
Mahigan
Senior member
Oh and as for pure speculation..
6-8 Shader engines is what I'm thinking Polaris/Vega will have.
I'm thinking that the Fury-X replacement*** (Big Vega 11) will have:
- 5,440 SIMDs clocked at 1.5Ghz in 85 CUs.
- 96-128 ROPs
- 340 Texture units
- 6-8 Brand new Geometry processors (one per Shader Engine)
- Probably a 4096-bit memory bus
- 2 HWSs (capable of 2 Wavefronts** each/cycle)
- 4 ACEs (capable of 1 Wavefront** each/cycle)
- 16GB HBM2
I'm thinking that the Fury replacement**** (Vega 11) will have:
- 4,736 SIMDs clocked at 1.5Ghz in 74 CUs.
- 96-128 ROPs
- 296 Texture units
- 6-8 Brand new Geometry processors (one per Shader Engine)
- Probably a 4096-bit memory bus
- 2 HWSs (capable of 2 Wavefronts** each/cycle)
- 4 ACEs (capable of 1 Wavefront** each/cycle)
- 8-16GB HBM2
I'm thinking that the R9 390x replacement (Big Polaris 11) will have:
- 4,096 SIMDs clocked at 1.5Ghz in 64 CUs.
- 96-128 ROPs
- 256 Texture units
- 6-8 Brand new Geometry processors (one per Shader Engine)
- 4,096-bit memory bus
- 2 HWSs (capable of 2 Wavefronts** each/cycle)
- 4 ACEs (capable of 1 Wavefront** each/cycle)
- 4GB HBM
I'm thinking that the R9 390 replacement (Polaris 11) will have:
- 3,584 SIMDs clocked at 1.5Ghz in 56 CUs.
- 96-128 ROPs
- 224 Texture units
- 6-8 Brand new Geometry processors (one per Shader Engine)
- 4,096-bit memory bus
- 2 HWSs (capable of 2 Wavefronts** each/cycle)
- 4 ACEs (capable of 1 Wavefront** each/cycle)
- 4GB HBM
** A wavefront is a set of 64 work items (threads).
*** Will target Titan class performance and pricing
**** Will target GTX 980 Ti class performance and pricing
My 2 cents.
Instead of Big Polaris, it could be Big Vega for the Titan class card and Vega for the GTX 980 Ti class card. Big Polaris would be the 390x replacement and Polaris the 390 replacement. This makes more sense to me. Polaris and Big Polaris could see a ROPs drop from 128 to 96 as well. I'm leaning towards AMD raising the core clock instead of increasing the amount of SIMD cores exponentially. This is mostly because of the 50-55% more performance that 14LPP offers over the older 28nm node.
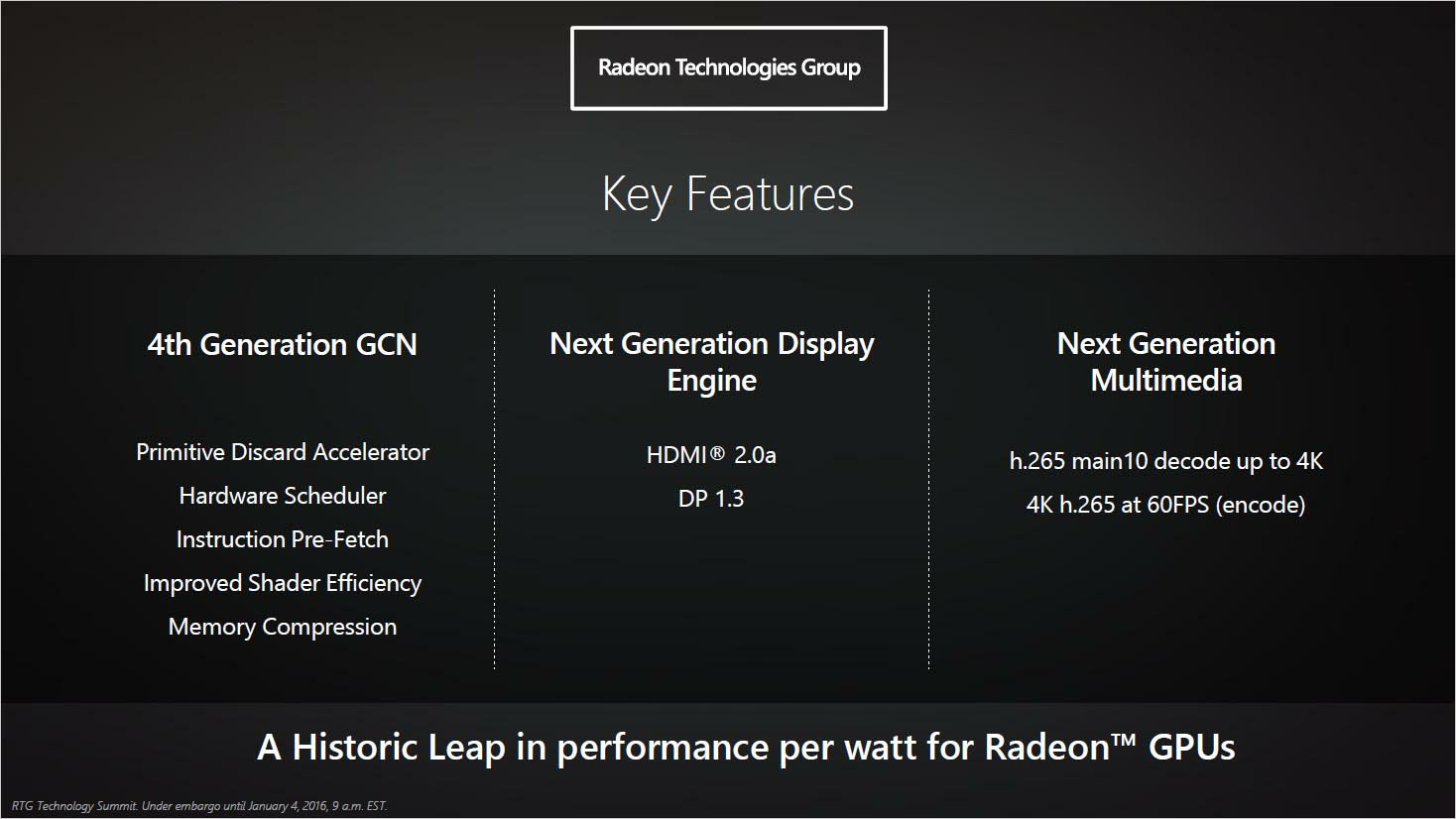 AMD have released info on some of the added features in Polaris namely:
AMD have released info on some of the added features in Polaris namely:
- Primitive Discard Accelerator (part of the new Geometry Processor) which will add Tessellation culling, meaning the same ability SM200 gained over Kepler. This means that Polaris will be able to remove unseen triangles from an image (Crysis 2 anyone?). This also means that Conservative Rasterization will be supported in Polaris.
- Instruction pre-fetching, which means that Polaris' hardware scheduler will now gain the ability to pre-fetch instructions from memory and into cache, with the newer and larger cache, this means improving CU utilization by cutting down on the latency when fetching instructions from memory (keeping the CUs filled with far less delays). Again, part of the advantages NVIDIA added to SM200 in order to gain better and more efficient use of available compute resources (SM200s +35% boost).
- New hardware scheduler (DirectX11 should get a nice boost). This is likely to deal with the API overhead GCN occurs under DX11.
- Improved Shader Efficiency, new and reorganized CUs. GCN is already superior to SM200 core for core . This is AMDs way of cutting back on some of the improvements NVIDIA have made with SM200 relative to Kepler.
- Memory Compression, improving upon Fiji here.
- New Command Processor, because Fiji used the same Commmand Processor as Hawaii (see 3DMark API Overhead DX12 test scores). This will allow more draw calls to be made and likely add support for some new, yet unannounced, features.
Oh, and they will overclock too. I am certain that AMD will rectify that embarrassment.
6-8 Shader engines is what I'm thinking Polaris/Vega will have.
I'm thinking that the Fury-X replacement*** (Big Vega 11) will have:
- 5,440 SIMDs clocked at 1.5Ghz in 85 CUs.
- 96-128 ROPs
- 340 Texture units
- 6-8 Brand new Geometry processors (one per Shader Engine)
- Probably a 4096-bit memory bus
- 2 HWSs (capable of 2 Wavefronts** each/cycle)
- 4 ACEs (capable of 1 Wavefront** each/cycle)
- 16GB HBM2
I'm thinking that the Fury replacement**** (Vega 11) will have:
- 4,736 SIMDs clocked at 1.5Ghz in 74 CUs.
- 96-128 ROPs
- 296 Texture units
- 6-8 Brand new Geometry processors (one per Shader Engine)
- Probably a 4096-bit memory bus
- 2 HWSs (capable of 2 Wavefronts** each/cycle)
- 4 ACEs (capable of 1 Wavefront** each/cycle)
- 8-16GB HBM2
I'm thinking that the R9 390x replacement (Big Polaris 11) will have:
- 4,096 SIMDs clocked at 1.5Ghz in 64 CUs.
- 96-128 ROPs
- 256 Texture units
- 6-8 Brand new Geometry processors (one per Shader Engine)
- 4,096-bit memory bus
- 2 HWSs (capable of 2 Wavefronts** each/cycle)
- 4 ACEs (capable of 1 Wavefront** each/cycle)
- 4GB HBM
I'm thinking that the R9 390 replacement (Polaris 11) will have:
- 3,584 SIMDs clocked at 1.5Ghz in 56 CUs.
- 96-128 ROPs
- 224 Texture units
- 6-8 Brand new Geometry processors (one per Shader Engine)
- 4,096-bit memory bus
- 2 HWSs (capable of 2 Wavefronts** each/cycle)
- 4 ACEs (capable of 1 Wavefront** each/cycle)
- 4GB HBM
** A wavefront is a set of 64 work items (threads).
*** Will target Titan class performance and pricing
**** Will target GTX 980 Ti class performance and pricing
My 2 cents.
Instead of Big Polaris, it could be Big Vega for the Titan class card and Vega for the GTX 980 Ti class card. Big Polaris would be the 390x replacement and Polaris the 390 replacement. This makes more sense to me. Polaris and Big Polaris could see a ROPs drop from 128 to 96 as well. I'm leaning towards AMD raising the core clock instead of increasing the amount of SIMD cores exponentially. This is mostly because of the 50-55% more performance that 14LPP offers over the older 28nm node.
- Primitive Discard Accelerator (part of the new Geometry Processor) which will add Tessellation culling, meaning the same ability SM200 gained over Kepler. This means that Polaris will be able to remove unseen triangles from an image (Crysis 2 anyone?). This also means that Conservative Rasterization will be supported in Polaris.
- Instruction pre-fetching, which means that Polaris' hardware scheduler will now gain the ability to pre-fetch instructions from memory and into cache, with the newer and larger cache, this means improving CU utilization by cutting down on the latency when fetching instructions from memory (keeping the CUs filled with far less delays). Again, part of the advantages NVIDIA added to SM200 in order to gain better and more efficient use of available compute resources (SM200s +35% boost).
- New hardware scheduler (DirectX11 should get a nice boost). This is likely to deal with the API overhead GCN occurs under DX11.
- Improved Shader Efficiency, new and reorganized CUs. GCN is already superior to SM200 core for core . This is AMDs way of cutting back on some of the improvements NVIDIA have made with SM200 relative to Kepler.
- Memory Compression, improving upon Fiji here.
- New Command Processor, because Fiji used the same Commmand Processor as Hawaii (see 3DMark API Overhead DX12 test scores). This will allow more draw calls to be made and likely add support for some new, yet unannounced, features.
Oh, and they will overclock too. I am certain that AMD will rectify that embarrassment.
Last edited:
Mahigan
Senior member
You can send as many queues as you want to a GPU at the same time.
He means executing work items from different queues concurrently.
SM200 supports: compute + compute, copy + compute, graphics + copy.
GCN supports: compute + compute, copy + compute, graphics + copy, compute + graphics.
Compute + Graphics is the performance boosting option and what AMD mean when they say "Asynchronous Compute". SM200 doesn't support this feature.
:\
Sorry, but you should read more about the API and GPUs. GPUs doing more than just "one job at a time". They need thousends of threads to hide the latency.
True, GCN is wider than SM200 though. Fiji is up to 163,840 threads wide and SM200 (GTX 980 Ti) is up to 45,056 threads wide.
Evidently, GCN can deal (and must deal) with more compute work in order to shine.
They dont offloading anything.
Sure they do, Static scheduling since Kepler, on NVIDIAs architectures, means that a significant portion of NVIDIAs scheduler is in the software driver. CPUs drive software drivers.
Last edited:
Mahigan
Senior member
Well, it's a complicated topic. Few people understand half the things written in GPU white papers.I know that he meant. Has still nothing to do with Multi Threaded Rendering.
I try my best to explain it all but even I make mistakes. Since last August, I've been brushing up on the latest GPUs after having been away from it all since the x800XT days.
Mahigan
Senior member
Looking forward to it 🙂The next week will be interesting for the Ashes fans. I saw the new RC update and it is remarkable.
Kollock stated that they changed most of the post processing effects. Should make for nice eye candy.
I'm also curious to see their multi-adapter implementation update 🙂
airfathaaaaa
Senior member
you cant really tell what is going on on the cpu if you find a way to distinguish normal cpu game load from what the gpu is throwing on the cpu tell meI know that he meant. Has still nothing to do with Multi Threaded Rendering.
oxide told us back on ocn that nvidia was offloading many of the processes on the cpu when the async was getting more and more involved into the game
Mahigan
Senior member
you cant really tell what is going on on the cpu if you find a way to distinguish normal cpu game load from what the gpu is throwing on the cpu tell me
oxide told us back on ocn that nvidia was offloading many of the processes on the cpu when the async was getting more and more involved into the game
Yeah, Kollock stated that they had to create many batches of short running shaders and signal often. More batches of short running shaders means more CPU usage due to the static scheduling nature of Kepler and Maxwell. This is why NVIDIA incur a larger CPU hit than AMD when running Ashes of the Singularity under DX12.
Mahigan
Senior member
Why more CPU usage?
More batches means more DirectX runtime CPU usage. And since you're scheduling more work, the NVIDIA static scheduler is doing more work which leads to more DirectX driver CPU occupancy.
NVIDIA apparently fixed this by removing some of the work being done with a driver update which led to the Post Processing and Lighting differences mentioned in this thread between GCN and SM200.
More batches means more DirectX runtime CPU usage. And since you're scheduling more work, the NVIDIA static scheduler is doing more work which leads to more DirectX driver CPU occupancy.
NVIDIA apparently fixed this by removing some of the work being done with a driver update which led to the Post Processing and Lighting differences mentioned in this thread between GCN and SM200.
guskline
Diamond Member
The next week will be interesting for the Ashes fans. I saw the new RC update and it is remarkable.
I suspect you have a NDA, but I would be thrilled if the update includes support for CF. My twin 290s below are pleading for help!😀
TheELF
Diamond Member
And that's the whole argument here,is "doesn't support" really the right wording?He means executing work items from different queues concurrently.
SM200 supports: compute + compute, copy + compute, graphics + copy.
GCN supports: compute + compute, copy + compute, graphics + copy, compute + graphics.
Compute + Graphics is the performance boosting option and what AMD mean when they say "Asynchronous Compute". SM200 doesn't support this feature.
True, GCN is wider than SM200 though. Fiji is up to 163,840 threads wide and SM200 (GTX 980 Ti) is up to 45,056 threads wide.
Evidently, GCN can deal (and must deal) with more compute work in order to shine.
SM200 can utilize all it's 45,056 threads with only graphics or only compute so doing async only adds complexity (context switching) and you get no boost or even lower performance.
GCN can not utilize all it's 163,840 threads with only graphics or only compute so it is the only arc that "supports" compute + graphics.
Same with the previous argument,1600x900 pixels divided through the available threads gives you a very small number of pixels for every thread so GCN is underutilized.
3840x2160 pixels divided through the available threads gives you a high number of pixels for every thread so sm200 is overburdened. (and so is GCN just not as much)
=GCN is always bottlenecked/bound/limited whatever unless you also do compute on the side.
Mahigan
Senior member
And that's the whole argument here,is "doesn't support" really the right wording?
SM200 can utilize all it's 45,056 threads with only graphics or only compute so doing async only adds complexity (context switching) and you get no boost or even lower performance.
GCN can not utilize all it's 163,840 threads with only graphics or only compute so it is the only arc that "supports" compute + graphics.
SM200 also has a lot of unused threads. GPU utilisation is also a problem for NVIDIA but not to the same degree as AMD.
The difference is that AMD can achieve peak utilisation with Asynchronous Compute (if used so a great extent), NVIDIA won't have that same perk.
Of course this relies on Asynchronous Compute being implemented by developers.
Same with the previous argument,1600x900 pixels divided through the available threads gives you a very small number of pixels for every thread so GCN is underutilized.
3840x2160 pixels divided through the available threads gives you a high number of pixels for every thread so sm200 is overburdened. (and so is GCN just not as much)
DirectX12 is showing that AMD were CPU bottlenecked at lower resolutions under DX11. Under DX12 demo's and Game Demo's, GCN does better at lower resolutions than SM200. An exact reversal of what we see under DX11.



The bottle neck here is Draw calls (command lists). Under DX11, SM200 can output 2-3x the amount of draw calls as GCN when using DX11s multi-threading features (which I've explained in previous posts). You can see the result of this in the 3DMark API over head test.

=GCN is always bottlenecked/bound/limited whatever unless you also do compute on the side.
No, GCN is API bottlenecked under DX11. GCN could fair better if the systems CPU was faster as GCN hammers the CPUs primary thread. You can clearly see this in the above 3DMark API over head test. A 290x's D3D11 Single threaded results are the same as its Multi-Threaded results. The R9 290x also has lower single threaded and multi-threaded figures when compared to a GTX 980.
Once running D3D12, the roles are reversed and the 290x is set free from the CPU bottle neck caused by the DX11 API over head.
The Command Processor on GCN is faster than the one on SM200 but the lack of deffered rendering and multi-threaded command listing in GCN hampers its performance under D3D11.
So a level playing field with DX12 means that Fury-X will compete nicely with a GTX 980 Ti, Fury will have no competition, 390x will compete with a GTX 980 and 390 will compete with a GTX 970. If you add Asynchronous Compute to a larger degree, the GCN cards will pull ahead.
Of course we're about to see Polaris and Pascal release and given the DX12 perks as well as the key Polaris architectural changes, Polaris will likely beat Pascal.
Last edited:
TheELF
Diamond Member
(furyx 980ti)DirectX12 is showing that AMD were CPU bottlenecked at lower resolutions under DX11. Under DX12 demo's and Game Demo's, GCN does better at lower resolutions than SM200. An exact reversal of what we see under DX11.
We have no idea of how big the CPU utilization is or how much async compute is going on, ~60FPS is lower then the 70-80FPS these cards are getting in tomb raider in 1080(you have to slow down for the GCN to be competitive? ) ,while 52-53FPS is ~exactly the same as the FPS they get in tomb in 1440...
that's the only thing we can say for sure just by looking at these benches.
Also one FPS difference is no difference, it's within statistical error.
Maybe because AMD has no driver that would do Multi-Threaded so of course it's the same.No, GCN is API bottlenecked under DX11. GCN could fair better if the systems CPU was faster as GCN hammers the CPUs primary thread. You can clearly see this in the above 3DMark API over head test. A 290x's D3D11 Single threaded results are the same as its Multi-Threaded results. The R9 290x also has lower single threaded and multi-threaded figures when compared to a GTX 980.
And yes it has lower single threaded and multi-threaded figures because it has a lot but slow shaders.
Again we have no idea of how much CPU time is spend on this.Once running D3D12, the roles are reversed and the 290x is set free from the CPU bottle neck caused by the DX11 API over head.
The Command Processor on GCN is faster than the one on SM200 but the lack of deffered rendering and multi-threaded command listing in GCN hampers its performance under D3D11.
Both are API bottlenecked under DX11 since sm200 also gains a lot under d3d12.
The Command Processor on GCN is faster than the one on SM200 just like a fx-8350 is faster then a i3-4170 but the lack of multi-threaded games hampers the fx's performance.
Speed of execution and amount of execution are not the same,the i3 is much faster in executing commands while the fx can execute more commands in a given time.
It's like running cinebench and saying that the FX is set free from the CPU bottle neck caused by the stupid single threaded games.
Let's face it,async is going to make games slower for everyone just like gameworks has done until now...
Mahigan
Senior member
(furyx 980ti)
We have no idea of how big the CPU utilization is or how much async compute is going on, ~60FPS is lower then the 70-80FPS these cards are getting in tomb raider in 1080(you have to slow down for the GCN to be competitive? ) ,while 52-53FPS is ~exactly the same as the FPS they get in tomb in 1440...
that's the only thing we can say for sure just by looking at these benches.
Also one FPS difference is no difference, it's within statistical error.
Actually we know how much Async compute is going on because both Lionhead and Oxide have told us. The answer is "very little". 5% of compute work items each.
Ashe's does more than Async. Kollock, an ashes dev, stated that they wouldn't use Ashes of the Singularity as an example of Async compute as they make very mild usage of the feature.
What's hammering the GPUs is the lighting. Each unit produces its own lighting.
Both engines are vastly different so you can't compare Tomb Raider to Ashes in terms of GPU bound scenarios. You can for CPU bound scenarios however.
Maybe because AMD has no driver that would do Multi-Threaded so of course it's the same.
And yes it has lower single threaded and multi-threaded figures because it has a lot but slow shaders.
No, I've proven to you that GCN has faster ALUs. ALUs have nothing to do with Draw Calls. Draw calls are execution bound while ALUs are compute performance bound.
Again we have no idea of how much CPU time is spend on this.
Both are API bottlenecked under DX11 since sm200 also gains a lot under d3d12.
Gaining a lot of potential draw calls is nice, but no game makes use of that many draw calls because no GPU can execute and process that many draw calls. Current game titles are most likely using between 1.1 and 2 Million draw calls. We can deduce this based on AMD GCNs lower performance under DX11 and performance boost under DX12 as well as the fact that current DX12 titles don't show noticeable gains for NVIDIAs SM200.
The Command Processor on GCN is faster than the one on SM200 just like a fx-8350 is faster then a i3-4170 but the lack of multi-threaded games hampers the fx's performance.
Speed of execution and amount of execution are not the same,the i3 is much faster in executing commands while the fx can execute more commands in a given time.
That's fair enough.
Let's face it,async is going to make games slower for everyone just like gameworks has done until now...
Come Hitman DX12 I'll be able to say "Told you so".
I have a 7950 upgraded to the 290 and would have upgraded to fiji if it was worth it but will upgrade to Polaris.Actually, not entirely true. It will be yet another boost injection for old GCN hardware (7970 FTW!). It means these old GPUs will serve their owners a little longer than their already retired competition. Which means amd will miss another sale compared to nvidia.
Someone who bought gtx680 already upgraded to 780 and later to 970 and will upgrade again to pascal for dx12.
Someone who bought 7970 a couple of years ago will be running dx12 games through 2016 on it
Obviously gcn held up better doesn't mean a person wouldn't make the same upgrades on both sides.
TheELF
Diamond Member
Isn't that the same difference? Every lighting effect is a (several? ) computation that has to be done in parallel/at the same time with all the other graphics,right?Actually we know how much Async compute is going on because both Lionhead and Oxide have told us. The answer is "very little". 5% of compute work items each.
Ashe's does more than Async. Kollock, an ashes dev, stated that they wouldn't use Ashes of the Singularity as an example of Async compute as they make very mild usage of the feature.
What's hammering the GPUs is the lighting. Each unit produces its own lighting.
Both engines are vastly different so you can't compare Tomb Raider to Ashes in terms of GPU bound scenarios. You can for CPU bound scenarios however.
If you look for GPGPU/OpenGL lighting is one of the most common things you'll find.
Yes,both engines are vastly different but if they both manage the same amount of utilization on both cards they will also provide the same FPS at the same resolution on both cards.
(Unless one engine would use an effect that one of the cards can't handle at all)
3DVagabond
Lifer
And that's the whole argument here,is "doesn't support" really the right wording?
SM200 can utilize all it's 45,056 threads with only graphics or only compute so doing async only adds complexity (context switching) and you get no boost or even lower performance.
GCN can not utilize all it's 163,840 threads with only graphics or only compute so it is the only arc that "supports" compute + graphics.
Same with the previous argument,1600x900 pixels divided through the available threads gives you a very small number of pixels for every thread so GCN is underutilized.
3840x2160 pixels divided through the available threads gives you a high number of pixels for every thread so sm200 is overburdened. (and so is GCN just not as much)
=GCN is always bottlenecked/bound/limited whatever unless you also do compute on the side.
This has to be the most twisted, convoluted argument I've ever read. This is just the never ending stream of excuses that we get because nVidia loses perf relative to AMD as resolution increases. You make it sound like you are actually getting something/anything extra from nVidia when in reality there is no functional performance difference in DX11 between the two uarch's.
Stunned I tell you, absolutely stunned.
+1
TheELF
Diamond Member
Well go ahead and give me your twisted, convoluted argument on why AMD loses perf relative to nVidia as resolution decreases,why is it harder to do less?This has to be the most twisted, convoluted argument I've ever read. This is just the never ending stream of excuses that we get because nVidia loses perf relative to AMD as resolution increases.
At least loosing performance when there is more data to perform on is logical,loosing less when there is more to perform is a special kind weird.
moonbogg
Lifer
Holy crap guys, this is all a little much. Does anyone even like this game? I know the DX stuff is interesting, but how is the game? I'm starting to realize that most people here are obsessed with GPU technology and they don't even have much use for the GPU in the first place. When I say "most people here" I actually mean "my damn self and maybe a few of you guys".
xthetenth
Golden Member
Well go ahead and give me your twisted, convoluted argument on why AMD loses perf relative to nVidia as resolution decreases,why is it harder to do less?
At least loosing performance when there is more data to perform on is logical,loosing less when there is more to perform is a special kind weird.
The idea of performance varying differently between different products as the constraining factor shifts due to varying demands is one of the fundamentals of using benchmarks to understand hardware. NV is less constrained by the dominant bottleneck at low resolutions, but that doesn't increase linearly with resolution so the bottlenecks shift to things AMD does better at. You're trying to turn it on its head but you're missing because you don't understand what you're talking about, it's not harder for AMD to do less, it's actually easier, but it's the exact thing for NV, the resolution matters to them more. AMD loses performance less slowly than NV when the resolution is increased, it's that simple, they don't lose performance at lower resolutions except in comparison to NV.
You'd understand these things if you read Mahigan's posts till you comprehended them. They're very good posts.
Mahigan
Senior member
I meant for NVIDIA, what hammers the GPU is the lighting. Hence why they removed some of the post processing effects in order to be competitive with AMD via a driver cheat (as confirmed by Kollock in not so many words). Kollock stated that both AMD and NVIDIA should look the same when rendering Ashes. He then asked "Did this occur after an NVIDIA driver update?".Isn't that the same difference? Every lighting effect is a (several? ) computation that has to be done in parallel/at the same time with all the other graphics,right?
If you look for GPGPU/OpenGL lighting is one of the most common things you'll find.
Yes,both engines are vastly different but if they both manage the same amount of utilization on both cards they will also provide the same FPS at the same resolution on both cards.
(Unless one engine would use an effect that one of the cards can't handle at all)
There is also the amount of rendered objects on the scene which hammers the GPU.
Only two post processing effects are running in parallel. Glare and point lighting. This might change with the new RC. Ashes Dev Kollock stated that they've redone most of the lighting effects.
Last edited:
TheELF
Diamond Member
It's a very very basic strategy game that hammers your GPU without any reason at all even with nothing at all going on on screen...Holy crap guys, this is all a little much. Does anyone even like this game? I know the DX stuff is interesting, but how is the game? I'm starting to realize that most people here are obsessed with GPU technology and they don't even have much use for the GPU in the first place. When I say "most people here" I actually mean "my damn self and maybe a few of you guys".
I know it's only a 650 but it should be able to do better then that,look at that crap, my celeron should be enough to drive a monster of a card.
This whole game is just a GPU benchmark and nothing more and that's probably why everybody only talks about the technical side.
Dx11 all low

Dx12 all low

Dx12 high, the few trees already kill half the performance...

TheELF
Diamond Member
That's exactly what I said earlierYou're trying to turn it on its head but you're missing because you don't understand what you're talking about, it's not harder for AMD to do less, it's actually easier, but it's the exact thing for NV, the resolution matters to them more. AMD loses performance less slowly than NV when the resolution is increased, it's that simple, they don't lose performance at lower resolutions except in comparison to NV.
You'd understand these things if you read Mahigan's posts till you comprehended them. They're very good posts.
Same with the previous argument,1600x900 pixels divided through the available threads gives you a very small number of pixels for every thread so GCN is underutilized.
3840x2160 pixels divided through the available threads gives you a high number of pixels for every thread so sm200 is overburdened. (and so is GCN just not as much)
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 25K
-

-

-
