
Haven't seen a new thread discussing it yet and loathe to use necromancy on an older thread, so here talking about the Neoverse V1 and future N2 cores just announced.
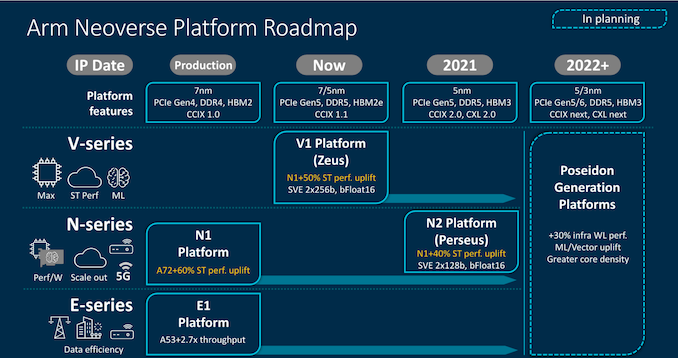
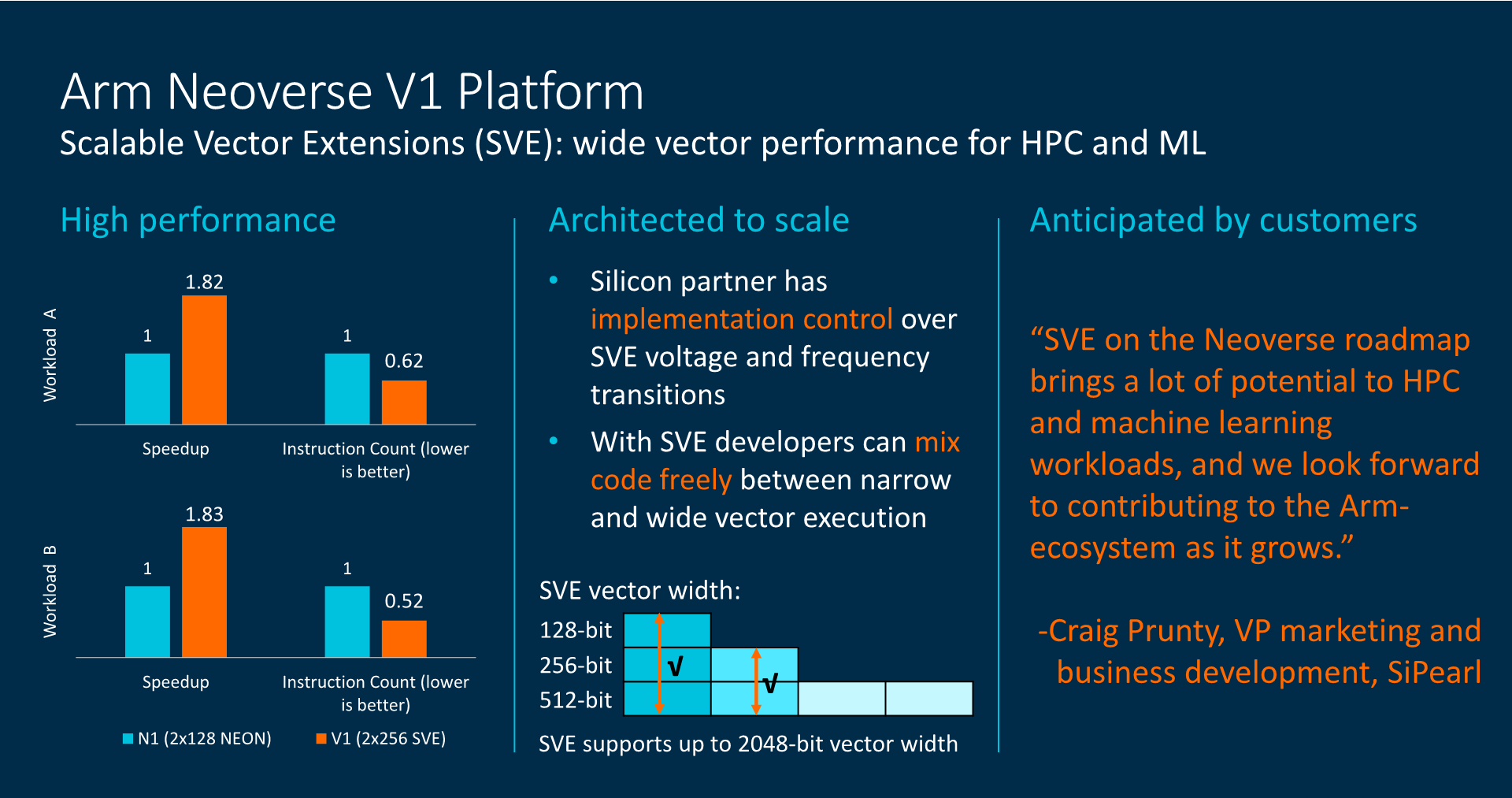
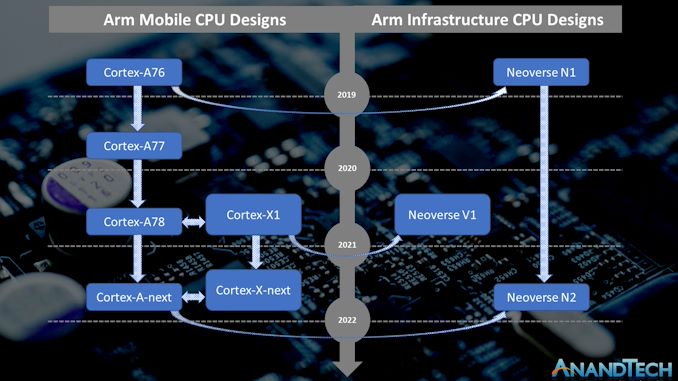
V1 (codename Zeus on previous roadmap) is available for licensing now and seems to be basically the Cortex X1/Hera core with 2x256b SVE1 units, projected as max 96C per socket and +50% IPC over N1.
N2 (codename Perseus) is coming next year and supposedly based on the Cortex Axx core to succeed A78/Hercules, so possibly Matterhorn - it has 2x 128b SVE units though ARM are tight lipped on whether they are SVE2 or not, projected as max 128C per socket and +40% IPC over N1.
Link here to the Anandtech article with lotsa depth.
V1 (codename Zeus on previous roadmap) is available for licensing now and seems to be basically the Cortex X1/Hera core with 2x256b SVE1 units, projected as max 96C per socket and +50% IPC over N1.
N2 (codename Perseus) is coming next year and supposedly based on the Cortex Axx core to succeed A78/Hercules, so possibly Matterhorn - it has 2x 128b SVE units though ARM are tight lipped on whether they are SVE2 or not, projected as max 128C per socket and +40% IPC over N1.
Link here to the Anandtech article with lotsa depth.
Last edited:
