
- Feb 6, 2010
- 4,542
- 727
- 126
http://www.anandtech.com/show/9518/the-mobile-cpu-corecount-debate
* It is common to have loads that are highly parallelized, utilizing many cores.
* big.LITTLE is a good design to make use of this, while providing optimal perf/watt across a wide performance range.
In short:http://www.anandtech.com/show/9518/the-mobile-cpu-corecount-debate/18
When I started out this piece the goals I set out to reach was to either confirm or debunk on how useful homogeneous 8-core designs would be in the real world. The fact that Chrome and to a lesser extent Samsung's stock browser were able to consistently load up to 6-8 concurrent processes while loading a page suddenly gives a lot of credence to these 8-core designs that we would have otherwise not thought of being able to fully use their designed CPU configurations.
[...]
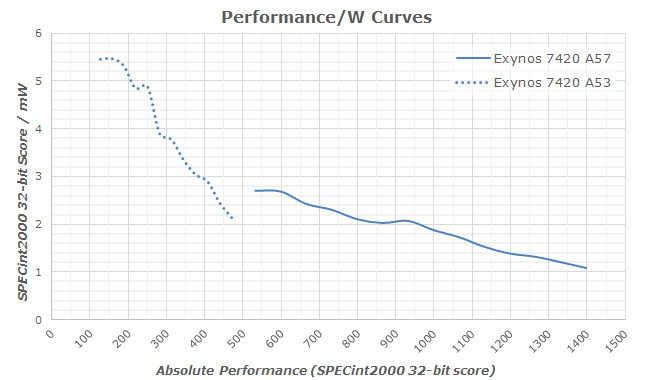
What we see in the use-case analysis is that the amount of use-cases where an application is visibly limited due to single-threaded performance seems be very limited. In fact, a large amount of the analyzed scenarios our test-device with Cortex A57 cores would rarely need to ramp up to their full frequency beyond short bursts (Thermal throttling was not a factor in any of the tests). On the other hand, scenarios were we'd find 3-4 high load threads seem not to be that particularly hard to find, and actually appear to be an a pretty common occurence. For mobile, the choice seems to be obvious due to the power curve implications. In scenarios where we're not talking about having loads so small that it becomes not worthwhile to spend the energy to bring a secondary core out of its idle state, one could generalize that if one is able to spread the load over multiple CPUs, it will always preferable and more efficient to do so.
[...]
In the end what we should take away from this analysis is that Android devices can make much better use of multi-threading than initially expected. There's very solid evidence that not only are 4.4 big.LITTLE designs validated, but we also find practical benefits of using 8-core "little" designs over similar single-cluster 4-core SoCs. For the foreseeable future it seems that vendors who rely on ARM's CPU designs will be well served with a continued use of 4.4 b.L designs.
* It is common to have loads that are highly parallelized, utilizing many cores.
* big.LITTLE is a good design to make use of this, while providing optimal perf/watt across a wide performance range.
