@name99
https://www.phoronix.com/scan.php?page=article&item=amazon-graviton2-benchmarks&num=8
is what I was looking for. Thanks! For anyone not interested in poring over all the specific results, the geometric mean is here:
https://www.phoronix.com/scan.php?page=article&item=amazon-graviton2-benchmarks&num=12
The bare metal results for Graviton2 are honestly not that great. Though when you consider its power consumption, I guess you can't really complain too much.
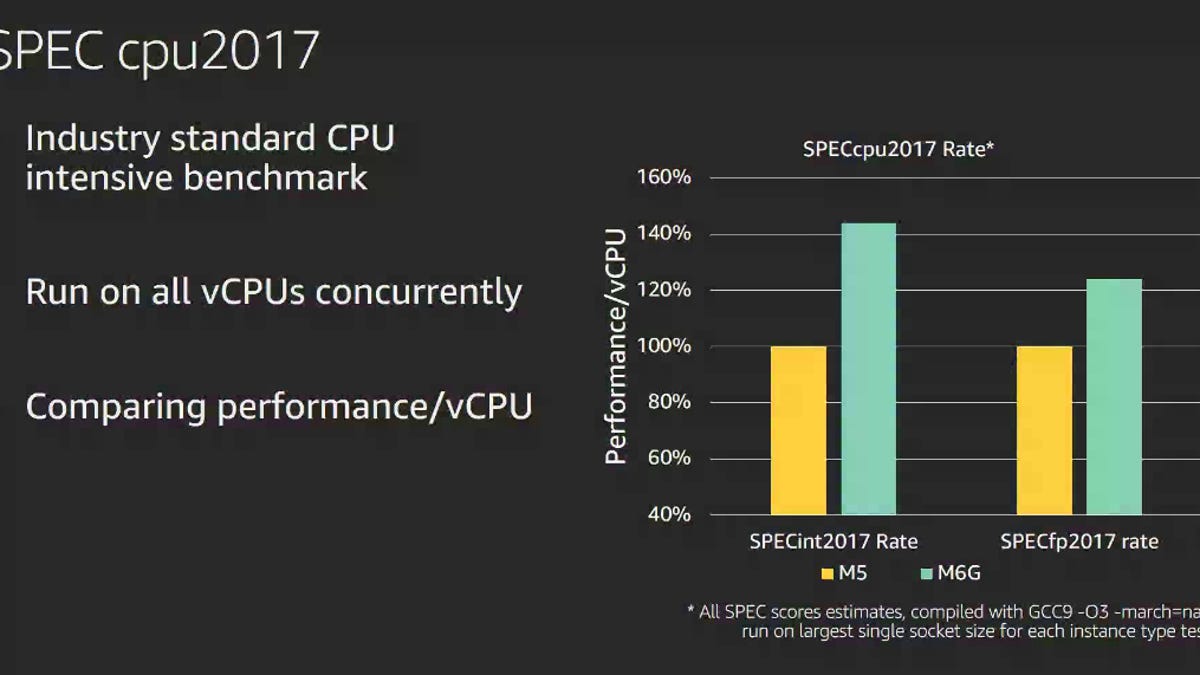
Uh, wait what? So now we've gone from "ARM SoCs cannot handle tasks involving lots of cores, lots of DRAM, or lots of IO" to "single socket Graviton 2 is only comparable to a single socket x86, not vastly superior"?
And this is a failure?
This is why no-one takes your arguments seriously; because you have no interest in actual understanding, only in litigating a particular point. And you keep changing your argument every time your current point gets refuted.
The argument was "What nobody seems to get, or understand, is that Apple and ARM AT THE MOMENT seems to be very strong in single core, non IO dependent benchmarks. They were designed for that purpose and do it well. But what about things that have high IO and multi-threaded requirements ? Blender, is just one. What about a huge database server, that serves Anandtech ? or Amazon ?"
That point has been answered. (And apparently at least part of the answer includes that Graviton 2 seems to handle virtualization with rather less overhead than x86...)
If you want to make an argument about cost to use these large SoCs, that has also been answered.
If you want to make an argument about the design time and team size required to create these SoCs that is also apparently answered -- certainly look at the size of the Marvel, Ampere, and Annapurna teams, and their turnover (*substantial* improvements every year to eighteen months) compared to Intel's size and pace.
Amazon has created a SoC that matches a substantial fraction of their needs. Period. If it doesn't match your needs, fine. (But, honestly, tell me you NEED a dual core Xeon Platinum system, and I'm going to call BS...) If you want to complain that it doesn't ship in a dual socket version (right now --- wait till the 2020 model...) or that it doesn't have feature X or feature Y, you need to explain to us
(a) why anyone cares.
(b) why this supposed lack is intrinsic to the ARM ecosystem, rather than not being provided because everyone involved (who, BTW, has a lot more serious incentives than you) simply doesn't consider it important or desirable.