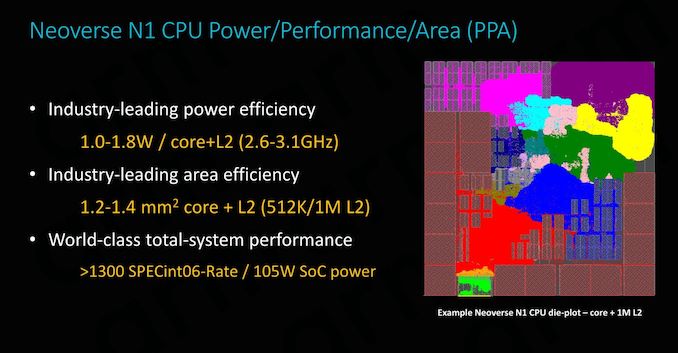
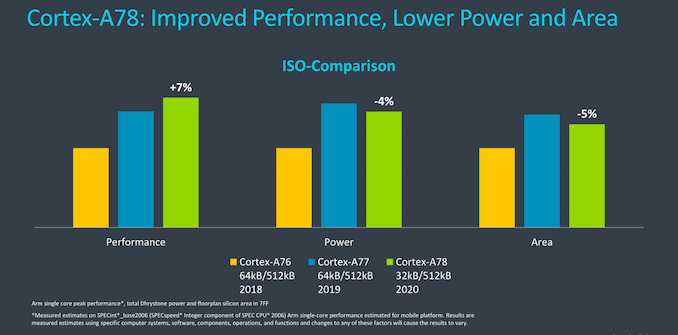
Oh, and A76 only has 512KB of L2 cache. And with it, its 1.26mm2.
According to ARM, the core in the A77 is 40-45% larger than A76. That's with both having 512KB L2 cache.
Revised figures:
A76/512KB L2 - 1.26mm2
A77/512KB L2 - 1.77mm2
A78/512KB L2 - 1.68mm2
Do you have source for A77 to be 40-45% larger because this looks like BS. ARM LLC with their focus at PPA would never release core degrading PPA so much (20% more IPC for 45% area). Andrei mentioned 17% more area which seems reasonable and alligned with further PPA improvement (20% more IPC for 17% more area).
A76/N1
A77:
"... the A77 is said to be only 17% bigger than the A76 – still significantly smaller than the next best microarchitecture from the competition."

www.anandtech.com
A78:
So you are right I have a mistake in the A76 area and this accumulated into A77 and A78 too. Correct data should be:
- A76 .... 1.2 mm2 0.5MB L2$
- A77 .... 1.4 mm2 0.5MB L2$ (+17% area)
- A78 .... 1.33 mm2 0.5MB L2$ (-5% area)
So it means the PPA advantage of A78 over Zen2 is
1.89x (instead wrong 2.28x). But it is still huge difference while taking into account 4,2 GHz clock for desktop Ryzen.
In servers there is no clock advantage because all server CPUs run basically around 3 GHz clock. And for iso-clock you have PPA ratio calculated from PPC/IPC and that's:
A78 .... PPC/IPC GB5.1 ... 306 pts/GHz
Zen2 ... PPC/IPC GB5.1 ... 286 pts/GHz .... 1.07x PPC ratio in favor of A78
Area ratio is 3.6 mm2 / 1.33 mm2 = 2.7x.
Overall iso-clock PPA is therefore 2.7 * 1.07 = 2.89x
That's probably an answer why ARM is running into servers first - low clocks can show full advantage in Performance per area metric. Graviton and Ampere Altra can get almost 3x more performance from same piece of silicon area. How do you think x86 vendors can fight this? It was no problem when old 32-bit ARMs had very laughable 1/5 PPC/IPC of x86 cores. But look how people stopped smiling to Gravion2 now even using an old A76 (8% lower PPC/IPC than Zen1) and yet slaughter Epyc basedn on Zen1 and offering higher performance per thread than Zen2 Epyc. Those smiles got freezed now. But today when A78 has higher PPC/IPC than Zen2? IMHO that's catastrophic situation what's coming soon.
The situation is that ARM Ampere Altra Max will have 128-cores at 7nm monolith while AMD Zen2 ends up at 64-core with big help of chiplet architecture (remember Rome has 1005 mm2 die size combined). Without that AMD would probably fall down to 32-core monolith or 4x 16-core Zen1-like. What if ARM vendors will adopt chiplet architecture too? That's horror scenario for both AMD and Intel.
I think everybody expects that every new x86 uarch spends more transistors than brings IPC - that's normal for high performance chips. Sunny Cove in Ice Lake was 18% IPC for 38% transitors increase. And Zen3 will be similar (20% IPC for 30% more transistors I expect). But this means it's PPA goes down while ARM LLC with A78 increased PPA. The PPA gap is constantly increasing in time. x86 is using/wasting transistors and energy for max performance while mobile environment forced ARM designers to think twice before they spend any additional transistors. It's in the genes. Only Intel is aware of this PPA situation and has back up plan with Snow Ridge server system with its Gracemont Atom cores. But I worry about AMD, they have no back up plan since they canceled their great ARM K12 (it seems K12 was brilliant back up plan how to unchaine AMD from x86 sinking ship and it was horrible idea for canceling it, what would we expect from people they developed BD, no wonder Keller left, he knew what's coming from ARM).
And new ARMv9 with much more efficient SVE2 SIMD vectors it can help to increase PPA even further. Take a look at Fukagu supercomputer how it can just with ARM CPUs beat supercomputers based on Nvidia GPUs. Who would expect that pure CPUs SC can beat GPUs in that area and become the most powerfull SC in several SC charts? Ok, I'm optimistic about ARM, but even the current PPA and PPC numbers shows that x86 will have huge problems to face current ARM server systems.
Not mentioning
economy point of view that Amazon can manufacture his 64-core
Graviton2 for 500 USD while AMD EPYC 7742 costs 7500 USD while delivering only 50% more performance in return. This is the second blade of ARM sword which will slaughter x86 in blood bath.

www.newegg.com