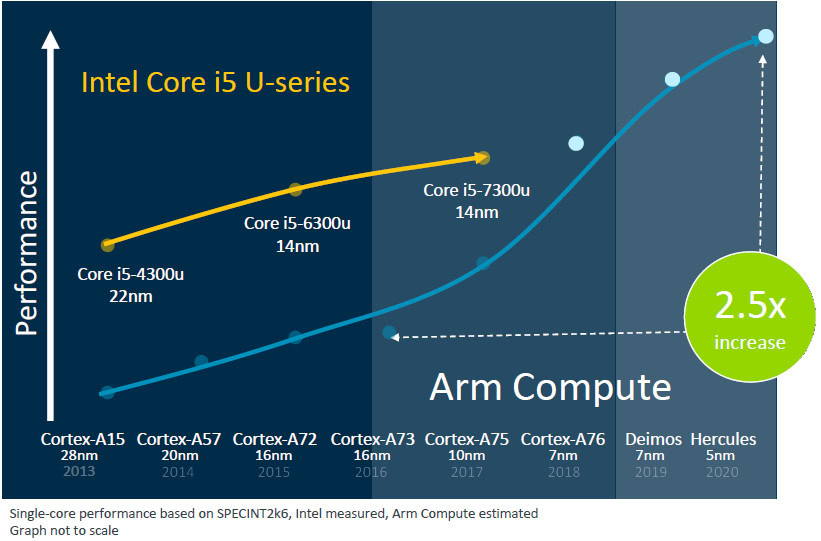
He talks about Geekbench5 score in MT which is true:
MT score is not fully comparable because A13 is only 2 big core + 4 little core and Intels are 4 big cores + SMT.
You would need to compare with 4 big core A12X from
iPad Pro GB5 score. And bang, an old
A12X has MT score of 4607 and outperforming any 4-core x86 laptop chip by huge margin (while running at just 2.5 GHz).
If we isolate just single core performance than results are very different and suddenly Apple A13 is outperforming Intel by large number:
And Apple A13 is running within 5W TDP, A12X 7W TDP...….. in compare to Intel laptops with 15W TDP and ST core running over 4 GHz (and still loosing in every way).
There is no point to answer some others - haters never write numbers and facts.
EDIT: Added Cortex A77 in new Snapdragon into comparison. It's 4+4 big.LITTLE and is on par with 4-core x86 Intels in MT load (with much lower power consumption). ST load is lower due to max clock at 2.8 GHz. IMHO biggest danger for Intel and AMD will come from generic Cortex cores such as this A77 or new A78. Don't forget that A77 has slightly higher IPC/PPC than Zen2 (+8% according to SPECint2006). This is huge milestone for generic Cortex core having higher IPC/PPC for the first time in history. Also very interesting from uarch point of view - A77 has 4xALU + 2xjump units, this half way to Apple's 6xALU design when Apple's core uses 4xALU + 2x simpleALU/jump units (and clearly wider than x86 stuck at 4xALU for decade). I can speculate that A78 might upgrade those 2xjump units into 2x simpleALU/jump in Apple style (seems logical and evolutional step to me but who knows). When every cheap Raspberry PI will have A78 with IPC/PPC higher than Ice Lake and Zen3, this is the biggest threat for x86 laptops and desktops. Apple is great technological demonstrator for future ARM Cortex cores though.
Just FYI Apple cores are now 7-wide, not 6.
"Width" is an imprecise term for OoO CPUs because there are many different chokepoints, but the A11 on appear to be able to SUSTAIN 7-wide operations (ie 7-wide decode and retire) with 6 (up from 4 in previous designs) ALU's.
There's still scope for Apple to go wider without breaking the bank. Two obvious next steps are
- 4th NEON unit, giving either 4-way NEON or 2-way SVE on 256-bit registers
- aggressive I-fusion of pairs of the form rA= rB op rC; rA=rA op rD, the significant point being back-to-back re-use of rA requires only one register allocation.
(And similar single-destination-register allocation pairs, for example the obvious load-store extensions)
For x86 the biggest difficulty in going wider is decode. For ARM decode is easy, the bigger difficulty in going wider are
- register rename (or more precisely resource allocation at the register rename stage)
- sustaining this wide I-fetch without stumbling, which requires a decoupled fetch engine, a very wide bus from I-cache to the I-queue, a very good branch predictor, and the ability to predict multiple branches per cycle (at the very least you need to be able to predict one fall-through and one taken per cycle, otherwise you're going to be killed by the branches, about 1/6 instructions, vs taken branches about 1/10 instructions).
But wider is not all there is to performance. You also want
- not to wait on RAM. This means very smart caches and very good prefetchers. Apple is stellar at both. ARM has stunning prefetchers (likely better than Apple A13, at least for some purposes. Presumably that will change with A14?) but their caches are more average.
- tricks in the core to defer work that is waiting on RAM. This is a HUGE topic, and it's unclear how much Apple (or anyone else) is doing. IMHO the best technique of immediate value is called Long Term Parking, published a few years ago. But it's unclear if Apple uses this yet.
- resource amplification. This refers to ways that you can get more value out of your core for given power, cycles, and area. The most common such technique is instruction fusion. Once again Apple is very aggressive here, with ARM lagging Apple a few years but still doing an OK job. There is still room for even more aggression by Apple, along with other techniques like instruction criticality prediction (which apparently no-one is yet using).
- additional types of speculation, for example load-value or load-address prediction. Qualcomm has been looking at these seriously for years now, they keep publishing (and their numbers keep getting better) but it's unclear their long-term plan. (Accumulate patents and try to license them to Apple or ARM?) Once again, it looks like no-one is actually using these yet.
Most of these ideas seem like they could perhaps be used by x86 as well (smarter caches, long term parking, value speculation, criticality). But x86 is so mired in complexity and baroque rules for exactly what has to be done for something else can be done (the memory ordering rules, which constrain various optimizations) that it's unclear if they can ever get there in the form of a CPU bug-free enough to be useful.
If you want to see a rough overview of where Apple is with respect to instruction units:
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.

www.anandtech.com
That gives A12 but A13 seems to be much the same. Of course the uncore matters as much as the core, which is why AnandTech gives as much space to describing the cache and memory controller for A12, then A13.
(Even so, AnandTech can't really get at either the cache smarts or the prefetchers, beyond the obvious issue of streams.)