-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AnandTech AMD Dives Deep On Asynchronous Shading
- Thread starter csbin
- Start date




Silverforce11
Lifer
As discussed in the DX12 threads, Async Compute & Shaders is the big feature of the new API, where CPU overhead reduction solves the CPU bottleneck, Async Compute/Shaders is whats going to reduce the rendering bottleneck.
With consoles being limited in power, such techniques to extract efficiency out of each shader (don't let it idle when it can process physics, shadows, lights, compute etc) is going to matter a lot moving forward. Imagine 2-4 years later with these console SoCs aging, developers will tap into any methods that can extract the last drop of performance from them.
AMD talked about these two features and how its going to be the next update to Mantle, to reduce GPU bottlenecks, but it never happened because DX12 & Vulkan has killed Mantle. But its great that this feature lives on!
With consoles being limited in power, such techniques to extract efficiency out of each shader (don't let it idle when it can process physics, shadows, lights, compute etc) is going to matter a lot moving forward. Imagine 2-4 years later with these console SoCs aging, developers will tap into any methods that can extract the last drop of performance from them.
AMD talked about these two features and how its going to be the next update to Mantle, to reduce GPU bottlenecks, but it never happened because DX12 & Vulkan has killed Mantle. But its great that this feature lives on!
Silverforce11
Lifer
Also there seems to be an error with this table?

Hawaii/Tonga has 8 ACEs, so 8x8 = 64 queues. That's 1 graphics or 63 (or 7x8 = 56) compute queues.
**Actually its even better than that, ACEs can execute the compute queues in parallel with the command processor so its always full capacity even when operating in mixed mode.
ie.
1 graphics + 8 compute PER ACE in Hawaii/Tonga.
That's 1 graphics + 64 compute simultaneously or 64 compute.
Here:

Hawaii/Tonga has 8 ACEs, so 8x8 = 64 queues. That's 1 graphics or 63 (or 7x8 = 56) compute queues.
**Actually its even better than that, ACEs can execute the compute queues in parallel with the command processor so its always full capacity even when operating in mixed mode.
ie.
1 graphics + 8 compute PER ACE in Hawaii/Tonga.
That's 1 graphics + 64 compute simultaneously or 64 compute.
Here:
Last edited:
Also there seems to be an error? From reading the article, AMD says each ACE can handle 8 queues. Hawaii/Tonga has 8 ACEs, so 8x8 = 64 queues. That's 1 graphics or 63 (or 7x8 = 56) compute queues. Actually its even better than that, ACEs can execute the compute queues in parallel with the command processor so its always full capacity when operating in mixed mode.
ie.
1 graphics + 8 compute PER ACE in Hawaii/Tonga.
That's 1 graphics + 64 compute simultaneously.
HD 7000 & Rx 240/250/270/280 : processeur de commandes x1 queue + 2 ACE x1 queue + 2 DMA engines
->Graphics/Compute/Copy avec limitations
HD 7790 & R7 260 : processeur de commandes x1 queue + 2 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
R9 285/290 : processeur de commandes x1 queue + 8 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
GTX 400/500/600/700 : processeur de commandes x1 queue + 1 DMA engine
->Pas de support
GTX 750/780/Titan : processeur de commandes x32 queues (limité) + 1 DMA engine
->Compute/Compute
GTX 900/Titan X : processeur de commandes x32 queues + 2 DMA engines
->Graphics/Compute/Copy
http://www.hardware.fr/news/14133/gdc-d3d12-amd-parle-gains-gpu.html
Noctifer616
Senior member
AMD talked about these two features and how its going to be the next update to Mantle, to reduce GPU bottlenecks, but it never happened because DX12 & Vulkan has killed Mantle. But its great that this feature lives on!
Actually, the Mantle documentation says that Mantle already supports Asynchronous Compute/DMA.
StereoPixel
Member
HD 7000 & Rx 240/250/270/280 : processeur de commandes x1 queue + 2 ACE x1 queue + 2 DMA engines
->Graphics/Compute/Copy avec limitations
HD 7790 & R7 260 : processeur de commandes x1 queue + 2 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
R9 285/290 : processeur de commandes x1 queue + 8 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
http://www.hardware.fr/news/14133/gdc-d3d12-amd-parle-gains-gpu.html
8 ACEs x8 queues = 64 Compute (+1 Compute) = 64+ Compute. That is correct.
But the first point (HD7970/280) is a bit wrong, because S.I. GCN (7970, 7870, etc.) support 2 hardware compute queues per ACE according to AMD's PDF OpenCL Programming Guide (see p. 1-13)
http://amd-dev.wpengine.netdna-cdn....AMD_OpenCL_Programming_Optimization_Guide.pdf
AMD GCN 1.2 (285) 1 Graphics + 8 ACEs = 64+ Compute (64+ queues)
AMD GCN 1.1 (290 Series) 1 Graphics + 8 ACEs = 64+ Compute (64+ queues)
AMD GCN 1.1 (260 Series) 1 Graphics + 2 ACEs = 16+ Compute (16+ queues)
AMD GCN 1.0+ (Kabini) 1 Graphics + 4 ACEs = 8+ Compute (8+ queues)
AMD GCN 1.0 (7000/200 Series) 1 Graphics + 2 ACEs = 4+ Compute (4+ queues)
NVIDIA Maxwell 2 (900 Series) 1 Graphics + 1 Compute = 32 Compute (32 queues)
NVIDIA Maxwell 1 (750 Series) 1 Graphics = 32 Compute (32 queues)
NVIDIA Kepler GK110 (780/Titan) 1 Graphics = 32 Compute (32 queues)
AMD has released much more technical PR involving DX12 than Nvidia. They've been more openly informative and excited than Nvidia. This kind of AMD needs to stay around. Stop doing the horrible cheese videos, stop allowing Huddy to spout idiotic comments. Instead, focus on their strengths (perf/$), future API readiness, and stay more agile in the market I.e. don't wait so long to drop prices in response to new competitive products.
I hope 390x puts the hurt on Titan X.
I hope 390x puts the hurt on Titan X.
Why should nVidia release powerpoint slides about an unreleased API?
BTW: Microsoft talked at nVidia's GTC about DirectCompute and DX12 and showed a demo of "multi-engine" aka Asynchronous Compute: http://on-demand.gputechconf.com/gtc/2015/video/S5561.html
BTW: Microsoft talked at nVidia's GTC about DirectCompute and DX12 and showed a demo of "multi-engine" aka Asynchronous Compute: http://on-demand.gputechconf.com/gtc/2015/video/S5561.html
AMD has released much more technical PR involving DX12 than Nvidia. They've been more openly informative and excited than Nvidia. This kind of AMD needs to stay around. Stop doing the horrible cheese videos, stop allowing Huddy to spout idiotic comments. Instead, focus on their strengths (perf/$), future API readiness, and stay more agile in the market I.e. don't wait so long to drop prices in response to new competitive products.
I hope 390x puts the hurt on Titan X.
This ^^
Although Huddy can be pretty informing at times, I think Roy has tendencies to be more of the commentator 🙂
monstercameron
Diamond Member
gcn is such a beast. THIs uarch might be the most future proof and flexible one yet.
AnandThenMan
Diamond Member
Easily. People talk about Nvidia's perf/watt advantage but at what cost? There is no free lunch and Nvidia has clearly skimped on features to bring down the transistor count.gcn is such a beast. THIs uarch might be the most future proof and flexible one yet.
GK110 introduced Hyper-Q with support for 32 concurrent queues. At the same time Tahiti only supported 4 Queues. Since then Hyper-Q is supported on every new GPU.
Only with Hawaii AMD supports more queues but even then 32 is enough for nVidia to fully utilized their compute cores.
Only with Hawaii AMD supports more queues but even then 32 is enough for nVidia to fully utilized their compute cores.
AnandThenMan
Diamond Member
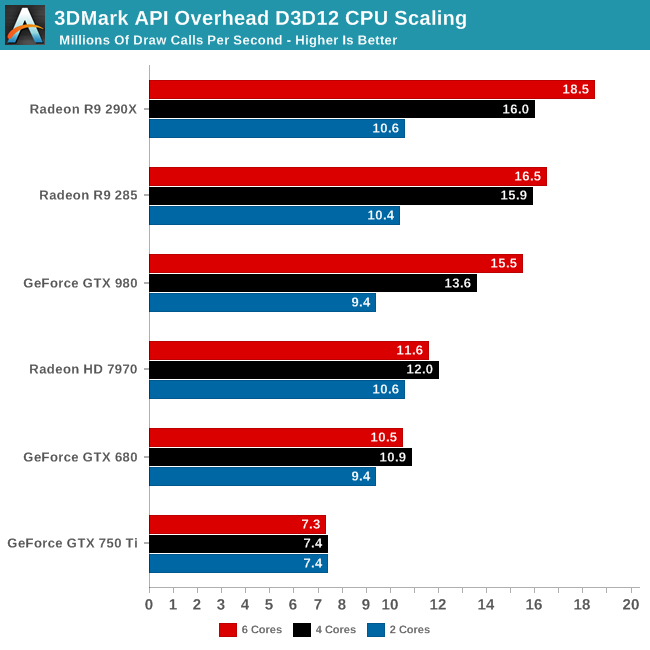
I think you need to go read the article and comprehend what it's all about.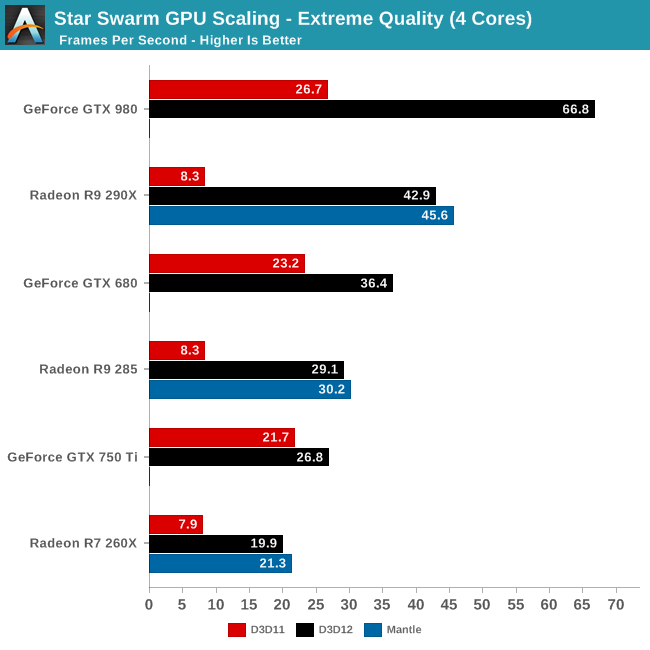
Yet AMD gets trounced in DX12 performance, so much for having 8 ACEs, 64 queues.
Yet AMD gets trounced in DX12 performance, so much for having 8 ACEs, 64 queues.
Yet another predictably partisan thread crap post.
StereoPixel
Member
Yet AMD gets trounced in DX12 performance, so much for having 8 ACEs, 64 queues.
The AMD DX12 driver then was not fully ready yet. AMD needs more time to improve driver. It's not Nvidia with big money.
The AMD DX12 driver then was not fully ready yet. AMD needs more time to improve driver. It's not Nvidia with big money.
It has nothing to do with the driver in Star Swarm. Star Swarm is command processor limited. They even implemented a batch optimized path for Mantle...
BTW: Despite all this talk about DX12 AMD hasnt mentioned once the new hardware features of the API. On the other hand nVidia and Intel have presented talks about DX12 about these new features. So much that AMD would support them.
Last edited:
DiogoDX
Senior member
GK110 introduced Hyper-Q with support for 32 concurrent queues. At the same time Tahiti only supported 4 Queues. Since then Hyper-Q is supported on every new GPU.
Only with Hawaii AMD supports more queues but even then 32 is enough for nVidia to fully utilized their compute cores.
On a side note, part of the reason for AMD's presentation is to explain their architectural advantages over NVIDIA, so we checked with NVIDIA on queues. Fermi/Kepler/Maxwell 1 can only use a single graphics queue or their complement of compute queues, but not both at once early implementations of HyperQ cannot be used in conjunction with graphics. Meanwhile Maxwell 2 has 32 queues, composed of 1 graphics queue and 31 compute queues (or 32 compute queues total in pure compute mode). So pre-Maxwell 2 GPUs have to either execute in serial or pre-empt to move tasks ahead of each other, which would indeed give AMD an advantage..
Unless you know more that Nvidia only Maxwell will support assync compute.
As discussed in the DX12 threads, Async Compute & Shaders is the big feature of the new API, where CPU overhead reduction solves the CPU bottleneck, Async Compute/Shaders is whats going to reduce the rendering bottleneck.
With consoles being limited in power, such techniques to extract efficiency out of each shader (don't let it idle when it can process physics, shadows, lights, compute etc) is going to matter a lot moving forward. Imagine 2-4 years later with these console SoCs aging, developers will tap into any methods that can extract the last drop of performance from them.
AMD talked about these two features and how its going to be the next update to Mantle, to reduce GPU bottlenecks, but it never happened because DX12 & Vulkan has killed Mantle. But its great that this feature lives on!
Imagine next year . . . 😀
DX12 supports three different command lists:
Graphics, Compute and Copy.
Pre Maxwell v2 architectures can use graphics + Copy or Compute + Copy.
Every architeture with Hyper-Q supports up to 32 concurrent compute tasks with input from 32 different streams (hosts).
Tahiti on the other hand only supported 4 compute queues and 1 graphics queue. But at this time there wasnt a API to support both at the same time.
Graphics, Compute and Copy.
Pre Maxwell v2 architectures can use graphics + Copy or Compute + Copy.
Every architeture with Hyper-Q supports up to 32 concurrent compute tasks with input from 32 different streams (hosts).
Tahiti on the other hand only supported 4 compute queues and 1 graphics queue. But at this time there wasnt a API to support both at the same time.
Silverforce11
Lifer
DX12 supports three different command lists:
Graphics, Compute and Copy.
Pre Maxwell v2 architectures can use graphics + Copy or Compute + Copy.
Every architeture with Hyper-Q supports up to 32 concurrent compute tasks with input from 32 different streams (hosts).
Tahiti on the other hand only supported 4 compute queues and 1 graphics queue. But at this time there wasnt a API to support both at the same time.
This is already known in the article and directly from MS.
Pre Maxwell 2, NV does not support Async Compute/Shaders. It's either graphics OR compute, not in tandem.
The entire point of Async Shaders is that it process graphics + compute at once, the compute part is not restricted to compute, but rendering processes as highlighted, such as lighting, shadows, post effects (including AA sampling) and the more traditional "compute" stuff like particle simulation and physics.
Now if more cross-platform games are developed with that in mind, ie. devs are extracting peak performance from GCN in consoles by using async compute to increase rendering or scene complexity, it would translate into PC games that run amazing on GCN + Maxwell 2 but ones that eat dirt on Kepler.
The reason GCN is more "future-proof" as some of us has suggested since its launch, is purely because of consoles and now DX12. The HFR article summarizes it very succinctly but correct, DX12 was "made for GCN" and NV had to adapt with Maxwell 2 or suffer. It is a good thing NV decided to optimize their uarch for DX12/Mantle.
swilli89
Golden Member
DX12 supports three different command lists:
Graphics, Compute and Copy.
Pre Maxwell v2 architectures can use graphics + Copy or Compute + Copy.
Every architeture with Hyper-Q supports up to 32 concurrent compute tasks with input from 32 different streams (hosts).
Tahiti on the other hand only supported 4 compute queues and 1 graphics queue. But at this time there wasnt a API to support both at the same time.
Unreal. Three posts up you were already proved super wrong. Like you got slapped in the face with how wrong you were. No.
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 25K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 24K
-

-
