
Ampere Altra Launched with 80 Arm Cores for the Cloud
The Ampere Altra 80-core Arm server CPU is upon us with 128 PCIe Gen4 lanes per CPU, CCIX, and dual-socket server capabilities. We assess the impact.

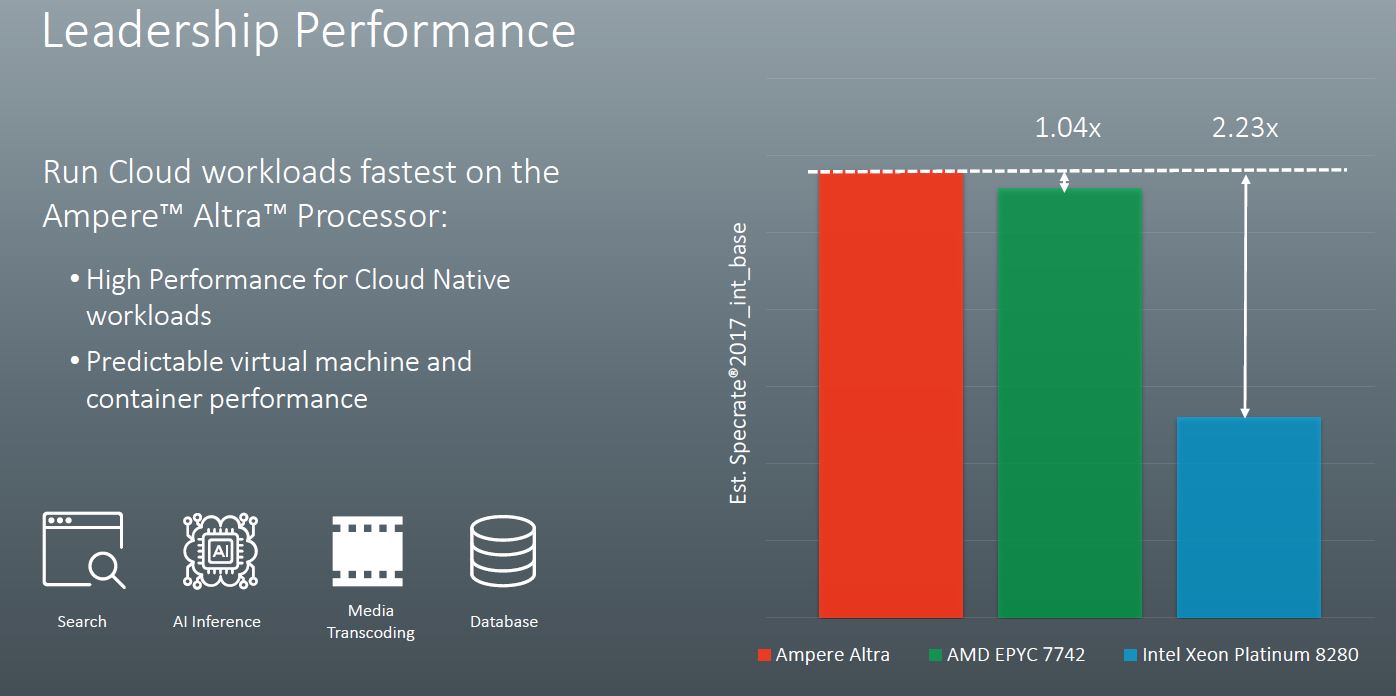


 Ampere Altra Performance Specrate2017_int_base
Ampere Altra Performance Specrate2017_int_base Ampere Altra End Note 1
Ampere Altra End Note 1How did he put it? Tweet's no longer available.EDIT: Or as Andreas kindly put it: https://twitter.com/i/web/status/1234883956849377281
What bothers me is not that they had to de-rate SPEC scores, it's a known fact that icc is applying unrealistic optimizations for instance. What bothers me is that they had to estimate that ratio. Don't they have access to Intel or AMD machines to make real measurements?
When we get to the endnotes, we see how Ampere got to these figures. The Altra part is a dual-socket 3.3GHz platform using GCC 8.2. Ampere did not disclose the TDP here but that is OK at this point. What we will note is that Ampere de-rated both the AMD EPYC 7742 and Xeon Platinum 8280 results by 16.5% and 24% respectively. This was done to adjust for using GCC versus AOCC2.0 and ICC 19.0.1.144. Ampere disclosed this, and it is a big impact. Arm servers tend to use GCC as the compiler while there are more optimized compilers out there for AMD and Intel. For some reference point that is why we showed both optimized and GCC numbers in our large launch-day ThunderX2 Review and Benchmarks piece.
That is likely a scalar comparison not accounting for SIMD/vector performance - the Altra is based on the Neoverse N1 design which in turn is a souped up A76 for server/datacenter markets, it has max 128 bit NEON units while the Epyc 2 series has 256 bit AVX2 units.Much PR fluff
First, Ampere is claiming performance from its parts in excess of the dual AMD EPYC 7742 by a small margin. That is AMD’s second-highest performing EPYC part behind the HPC focused AMD EPYC 7H12 but it is also AMD’s highest-end mainstream SKU. Ampere Altra is also claiming a massive estimated Specrate2017_int_base figure over the dual Intel Xeon Platinum 8280 configuration. As we discussed in our Big 2nd Gen Intel Xeon Scalable Refresh piece, Intel has a new Xeon Gold 6258R which is a better comparison point now. While we expect the Xeon Gold 6258R to perform like the Xeon Platinum 8280, comparable numbers have not been published. Ampere, to its credit, is not using the Platinum 8280 list price so this is well done.
When we get to the endnotes, we see how Ampere got to these figures. The Altra part is a dual-socket 3.3GHz platform using GCC 8.2. Ampere did not disclose the TDP here but that is OK at this point. What we will note is that Ampere de-rated both the AMD EPYC 7742 and Xeon Platinum 8280 results by 16.5% and 24% respectively. This was done to adjust for using GCC versus AOCC2.0 and ICC 19.0.1.144. Ampere disclosed this, and it is a big impact. Arm servers tend to use GCC as the compiler while there are more optimized compilers out there for AMD and Intel. For some reference point that is why we showed both optimized and GCC numbers in our large launch-day ThunderX2 Review and Benchmarks piece.
This de-rate practice for ICC and AOCC is common in the industry and Ampere disclosed it clearly. We will note that while it is not enough to tip the balance on the Xeon side, it does mean that the 2019-era AMD EPYC 7742 can provide more performance than the future 2020-era Ampere Altra 3.3GHz.
Ampere in the slides above states that the Altra has a 3.0GHz maximum turbo. It is interesting that they are using a part here that is running at 10% higher clock speeds, especially with a 4% lead over AMD.
I can't comment on the Ampere, but you'll have equal-compiler figures from us on Graviton2/Cascade/EPYC.What bothers me is not that they had to de-rate SPEC scores, it's a known fact that icc is applying unrealistic optimizations for instance. What bothers me is that they had to estimate that ratio. Don't they have access to Intel or AMD machines to make real measurements?
For reference, the above quoted ServeTheHome article shows that the ratio icc vs gcc 7 for Gold 6148 is ~0.65 (so 35% de-rate) and ~0.70 for AOCC on EPYC 7601.
By the way @Det0x, it would have been more honest to provide a link to the article where you copied verbatim your message from: https://www.servethehome.com/ampere-altra-80-arm-cores-for-cloud/
They're stronger IPC than Intel/AMD, but not by a lot.Based on the numbers they pushed out, these CPUs have much lower IPC than competitors. It's late so I won't get into it, but do the math...
There's some SIMD in SPEC, but it's not like it's a math crunching HPC test that fully utilises it. For the workloads that it's meant for, there's absolutely no problem with the throughput.That is likely a scalar comparison not accounting for SIMD/vector performance - the Altra is based on the Neoverse N1 design which in turn is a souped up A76 for server/datacenter markets, it has max 128 bit NEON units while the Epyc 2 series has 256 bit AVX2 units.
They're stronger IPC than Intel/AMD, but not by a lot.
I can't comment on the Ampere, but you'll have equal-compiler figures from us on Graviton2/Cascade/EPYC.
They're stronger IPC than Intel/AMD, but not by a lot.
There's some SIMD in SPEC, but it's not like it's a math crunching HPC test that fully utilises it. For the workloads that it's meant for, there's absolutely no problem with the throughput.
Can't agree more, I was wondering how does one even do this IPC comparison. Intel x86 vs AMD x86 would probably make some sense.No! just no!
Even if accept that instructions are simpler, latest x86 decodes more, fits more in the cache, and has much wider execution units. Not to mention, SSE/AVX/AVX2 have way more custom instructions than NEON.
Just the base math
zen2 2.0 x 64 * 1.04 = ampere 3.0 x 80
in a single benchmark is enough to refute this.
It didn't occur to you that Andrei is talking about results *he* measured himself on Graviton2? That's how I understood his claim.No! just no!
Even if accept that instructions are simpler, latest x86 decodes more, fits more in the cache, and has much wider execution units. Not to mention, SSE/AVX/AVX2 have way more custom instructions than NEON.
Just the base math
zen2 2.0 x 64 * 1.04 = ampere 3.0 x 80
in a single benchmark is enough to refute this.
It didn't occur to you that Andrei is talking about results *he* measured himself on Graviton2? That's how I understood his claim.
It didn't occur to you that Andrei is talking about results *he* measured himself on Graviton2? That's how I understood his claim.
Even if you live in the land of the obtuse and count aggregate instruction throughput across all cores in a system I hope you're also counting more clocks since all the cores together tick more together right?No! just no!
Even if accept that instructions are simpler, latest x86 decodes more, fits more in the cache, and has much wider execution units. Not to mention, SSE/AVX/AVX2 have way more custom instructions than NEON.
Just the base math
zen2 2.0 x 64 * 1.04 = ampere 3.0 x 80
in a single benchmark is enough to refute this.
Last I checked the retired instruction count of x86 vs AArch64 differed less than 10% so let's also retire that broken old argument. Thank you for bringing this up I should cover it in the review to end this for good.Can't agree more, I was wondering how does one even do this IPC comparison. Intel x86 vs AMD x86 would probably make some sense.
Just try to compile some day to day code with index operation from heap and see.
If you remove the -O/-s flag for readability, you can see the x86 code has lesser instructions for the C/C++ function than for arm64.
Regarding the int benchmarks, it makes me wonder how that is being made.
x86 has so many complex instructions and I am certain most compiler fuses a bunch of steps in one instruction wherever possible for most application code.
Yes.It didn't occur to you that Andrei is talking about results *he* measured himself on Graviton2? That's how I understood his claim.
Even if you live in the land of the obtuse and count aggregate instruction throughput across all cores in a system I hope you're also counting more clocks since all the cores together tick more together right?
I find MT IPC discussions stupid as at that point you're not discussing about a core's microarchitectural IPC capabilities anymore but the overlying system's memory capabilities. Why are you even accounting for the notion of cores here? AMD/Intel use SMT while Arm fits in two cores in the space of one x86 core. N1 single-threaded IPC is higher than Rome and Cascade lake, and "system-wide"-IPC it's also higher than at least Cascade (didn't get to do that comparison to Rome yet).
As a note, N1 in the server chips has very notably higher IPC than a mobile A76 because it has quite bigger caches and a significantly better memory subsystem. It is very very good.
I don't understand what you're even trying to convey here, I was bringing up how system wide IPC is a stupid metric since you were normalising "clock" for a system wide metric, at the same time I can normalise processors as being a system wide metric at which point it doesn't matter how many cores it takes to achieve the system wide throughput result.Ehh if you're not running at your best available clock, you better be doing avx512. Not all instructions are the same, nor are compilers, platforms, cooling, etc.
I'm talking about an aggregate wide variety of workloads. IPC matters to single-threaded workloads because that's a limitation of the serial nature of the workload. Once you can go parallel, if you can reach high throughput though SMT/IPC or just more cores it shouldn't matter as long as per-thread perf doesn't tank dramatically. In this case the N1 is better in both regards.Single / Multi threaded are just metrics. What you're saying here about memory, die area, or any other factor goes straight to the point. IPC, while often considered a direct reflection of computer performance, is very relative to the workload and platform.
A certain niche of what? Quit beating around the bush and talk in actual workloads. Are you saying SPEC doesn't cover real workloads? There's a very clear delineation of workload types that roughly fall into the categories of high compute/high execution bottle-necked and high memory pressure bottle-necked, with varying shades of other small aspects between those two.Estimates, rates, synthetics, overwhelmingly stream oriented workloads, may favor a certain niche. Other workloads not so much.
SIMD is mostly irrelevant for non-HPC workloads, games probably the only other everyday area where they matter more. Have you actually compiled a large codebase with and without AVX? The difference is 5-10%. Saying NEON doesn't even reach SSE is insane, please name one thing you cannot do with NEON? High-density matrix operations is literally the only thing at which they aren't as fast right now, until you see Arm's 2x256bit core in 2 years. But again you saw how AMD did just dandy with 2x128b in Zen and also beats Intel with 2x256b in Zen2.x86 is on it's forth major iteration of simd. neon while moving fast, has still not even reached the level of sse.
