- Jun 1, 2017
- 5,248
- 8,463
- 136
I think this has been posted in four threads so far or something like that. Let's talk about these interesting slides in this dedicated thread instead.
@rickxross mentioned this Japanese article with plenty English slides about AMD's efforts involved in moving to TSMC's N7 7nm node.
@uzzi38 mentioned an article at WikiChip discussing the capabilities and challenges with going with 7nm.
The slides are from a talk by AMD's Teja Singh at the ISSCC 2020 (International Solid-State Circuits Conference, ended two days ago).
AMD improved switching capacitance by ~9% beyond the node change.

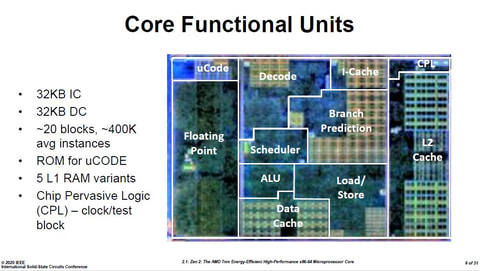
Slides include some annotated dies!

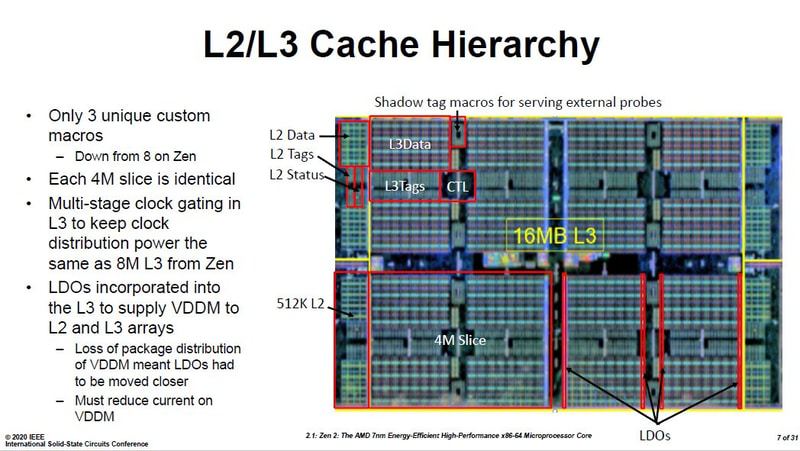
AMD doesn't mention desktop, instead it's HEDT/server.

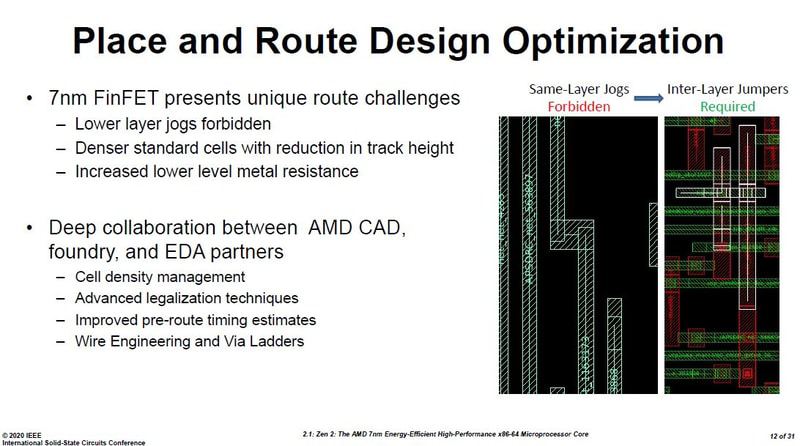
Layouting the placement of the differently sized cells is tricky, leaving many gaps.

Routing no longer can have corners at the same layer, instead requires 3D inter-layer jumpers.
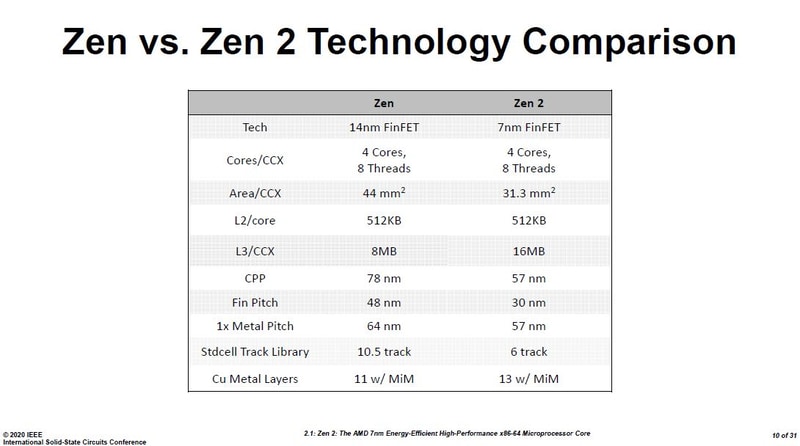
Switching capacitance improved a lot further from going from 14nm to 7nm node.

Summary of the perf/watt improvements.

The resulting frequency/power curve.

As well as the frequency voltage curve.

CCD = 3.8 bil FETs @ 74mm², Server IOD = 8.34 bil FETs @ 416mm², Client IOD = 2.09 bil FETs @ 125mm²

Cost per yielded mm² for a 250mm² die doubled going from 14/16nm to 7nm.

Zeppelin comprised of 56% core + L3$ area. CCD increased that to 86%.

One more annotated die! Wonder what the SMU comprises of, is it ARM based?

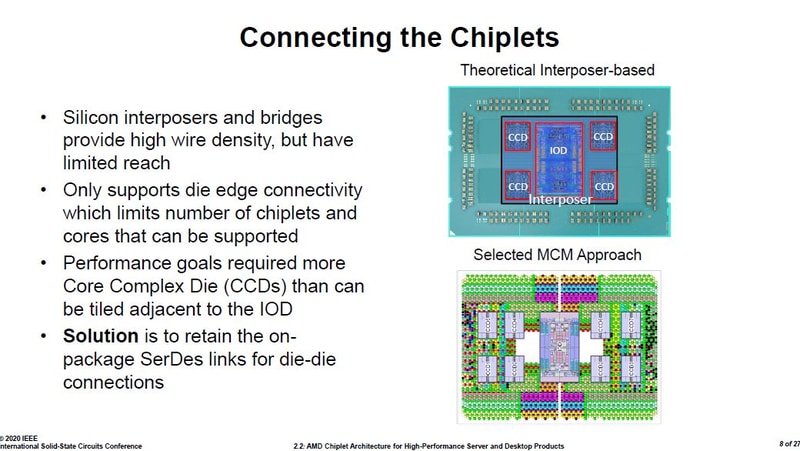
Interposer was under consideration, but dies would have to be much closer and only 4 chiplets would have combined then, limiting max core count to 32 compared to the 8 chiplets and 64 cores possible with the chosen MCM approach.

Improvements in the IFOP SerDes architecture.

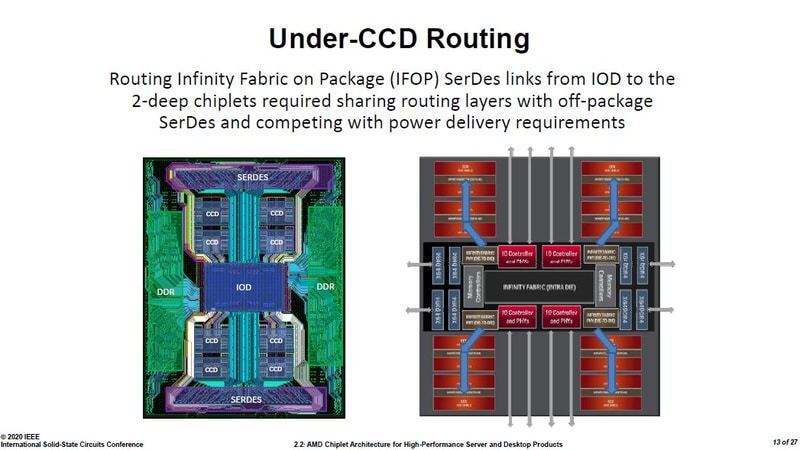
Annotated routing map, that looks cramped!
And since CCD is 7nm and IOD is 14/12nm the bump pitch differ as well. Change to an interface that's compatible with both.

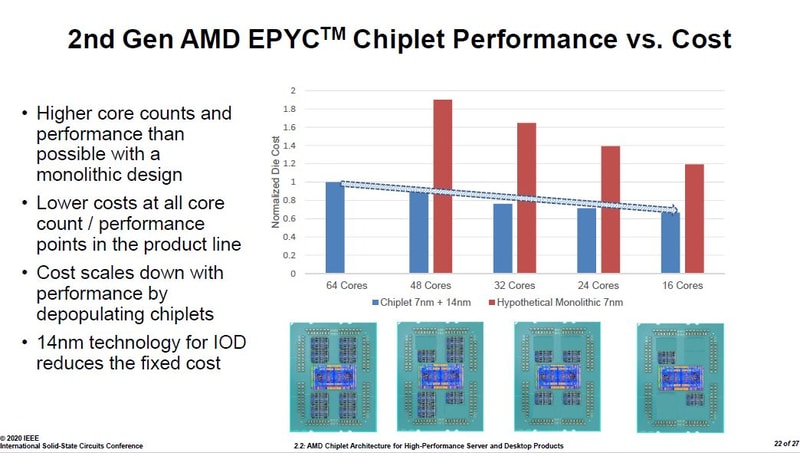
The resulting margin is bigger the more cores it is used for, pretty much the opposite than with monolith dies.
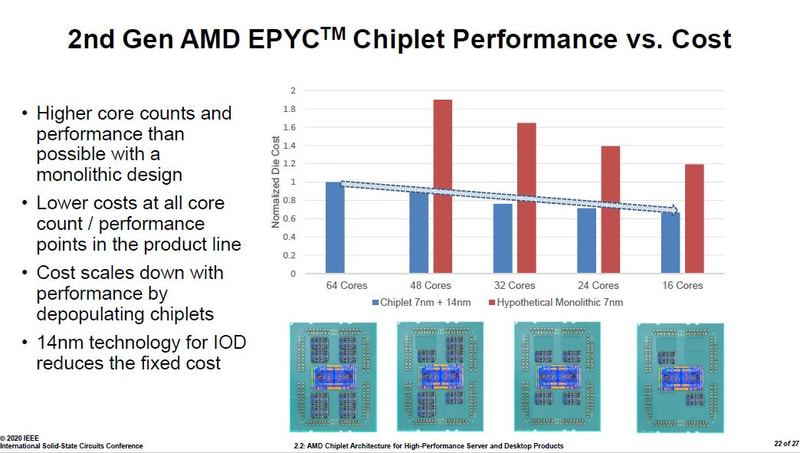
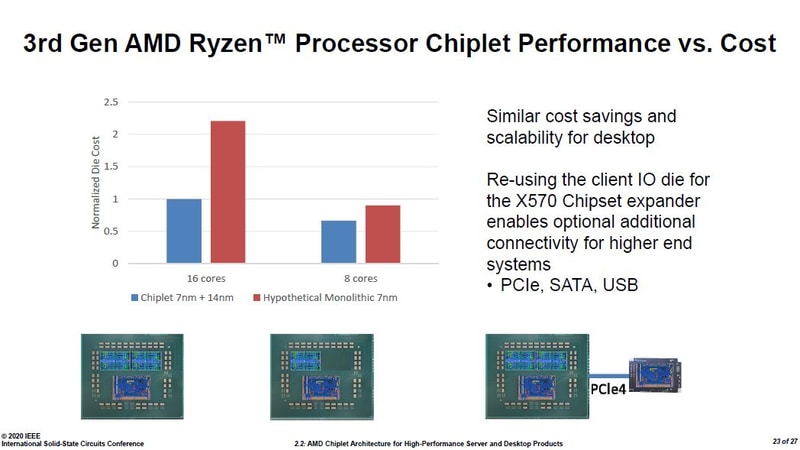
On desktop the difference is even more stark. These show AMD doesn't need to hold back with many cores, instead it would profit even more if people where to buy more of the most cores chips as those have way higher margins while the cost for the dies barely increases.
@rickxross mentioned this Japanese article with plenty English slides about AMD's efforts involved in moving to TSMC's N7 7nm node.
@uzzi38 mentioned an article at WikiChip discussing the capabilities and challenges with going with 7nm.
The slides are from a talk by AMD's Teja Singh at the ISSCC 2020 (International Solid-State Circuits Conference, ended two days ago).
AMD improved switching capacitance by ~9% beyond the node change.
Slides include some annotated dies!
AMD doesn't mention desktop, instead it's HEDT/server.
Layouting the placement of the differently sized cells is tricky, leaving many gaps.
Routing no longer can have corners at the same layer, instead requires 3D inter-layer jumpers.
Switching capacitance improved a lot further from going from 14nm to 7nm node.
Summary of the perf/watt improvements.
The resulting frequency/power curve.
As well as the frequency voltage curve.
CCD = 3.8 bil FETs @ 74mm², Server IOD = 8.34 bil FETs @ 416mm², Client IOD = 2.09 bil FETs @ 125mm²
Cost per yielded mm² for a 250mm² die doubled going from 14/16nm to 7nm.
Zeppelin comprised of 56% core + L3$ area. CCD increased that to 86%.
One more annotated die! Wonder what the SMU comprises of, is it ARM based?
Interposer was under consideration, but dies would have to be much closer and only 4 chiplets would have combined then, limiting max core count to 32 compared to the 8 chiplets and 64 cores possible with the chosen MCM approach.
Improvements in the IFOP SerDes architecture.
Annotated routing map, that looks cramped!
And since CCD is 7nm and IOD is 14/12nm the bump pitch differ as well. Change to an interface that's compatible with both.
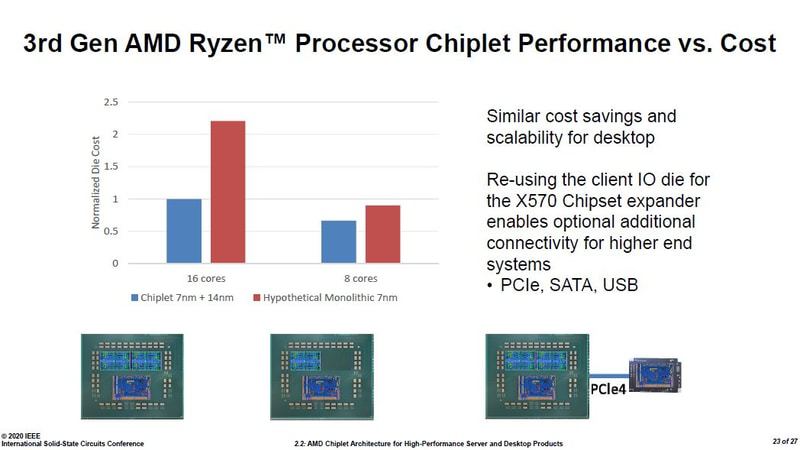
The resulting margin is bigger the more cores it is used for, pretty much the opposite than with monolith dies.
On desktop the difference is even more stark. These show AMD doesn't need to hold back with many cores, instead it would profit even more if people where to buy more of the most cores chips as those have way higher margins while the cost for the dies barely increases.
Last edited: