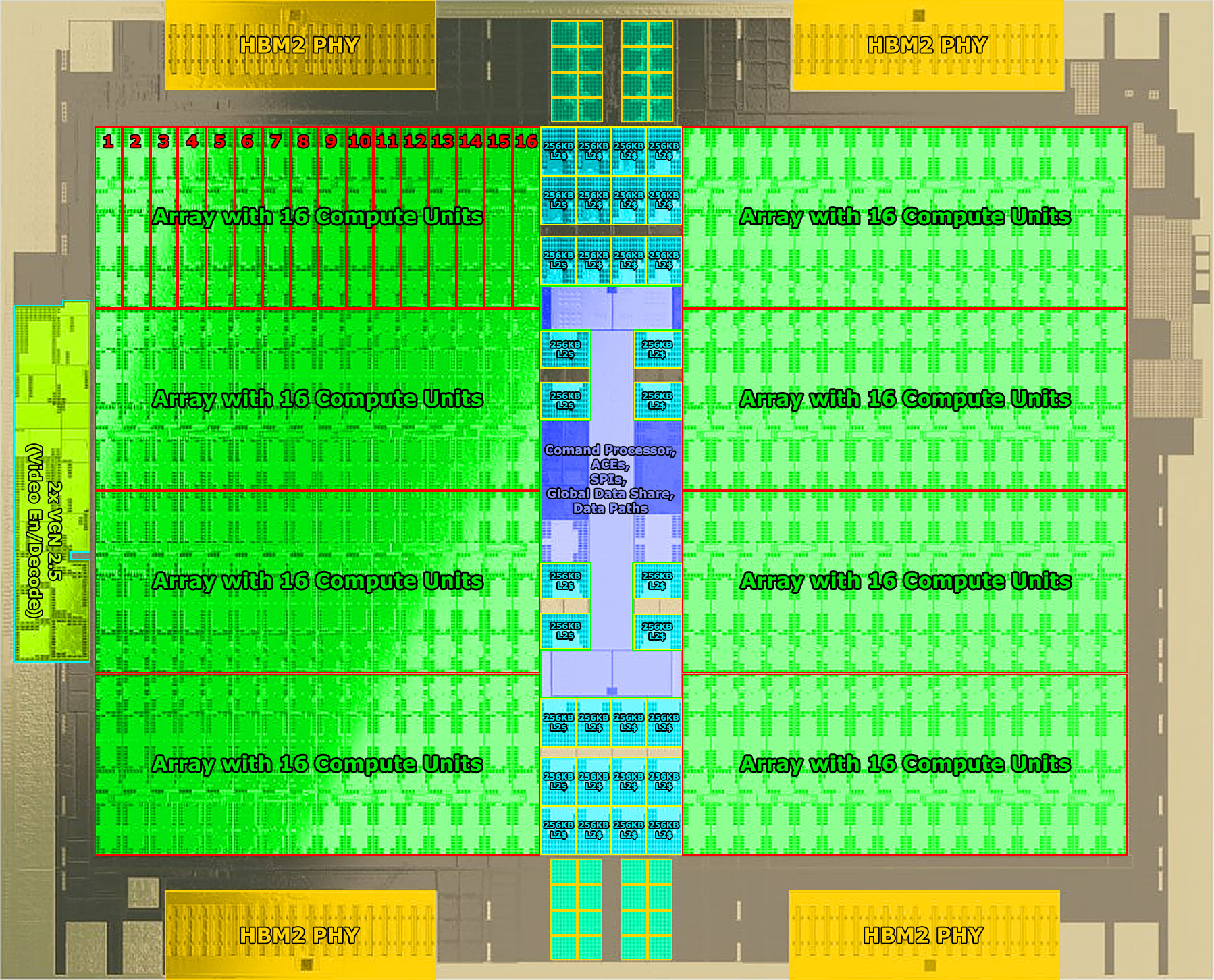
Seems like AMD is truly creating a permanent separation in GPU between gaming and compute focused uArch - the new compute focused uArch family is called CDNA.

Hopefully this doesn't mean any significant drop in async compute and general Vulkan compute performance with RDNA.
Hopefully this doesn't mean any significant drop in async compute and general Vulkan compute performance with RDNA.