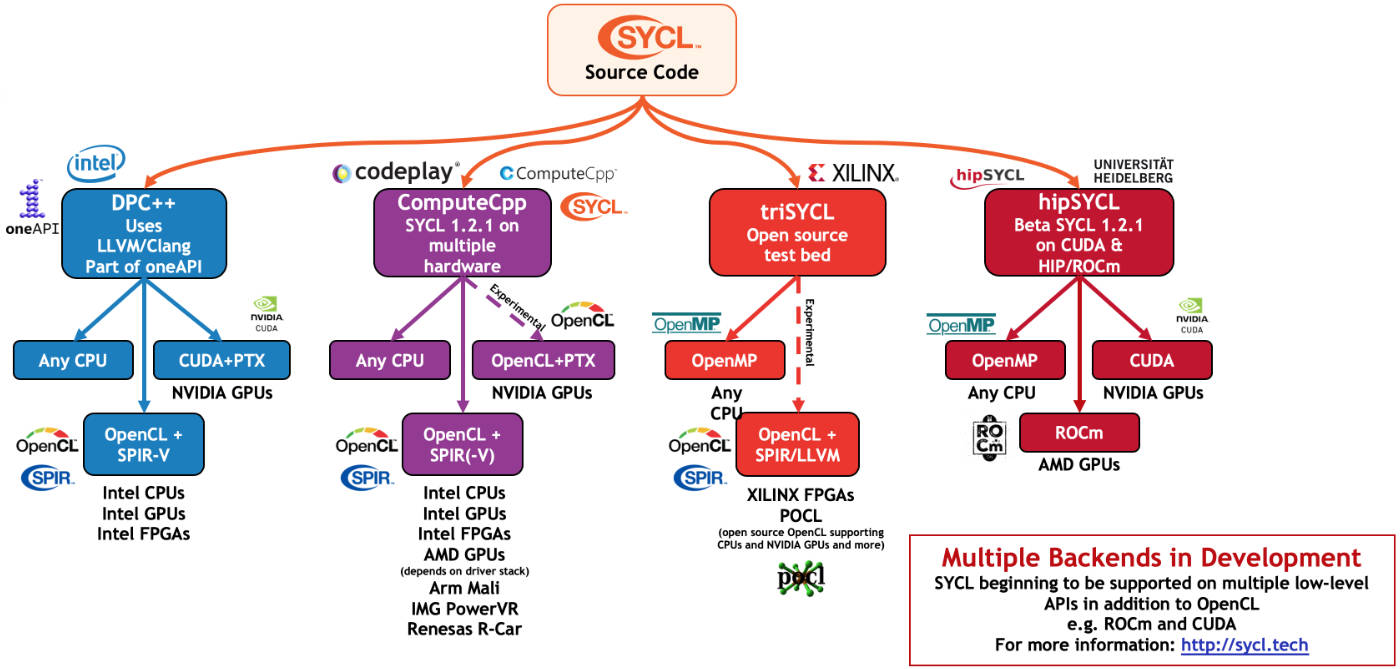
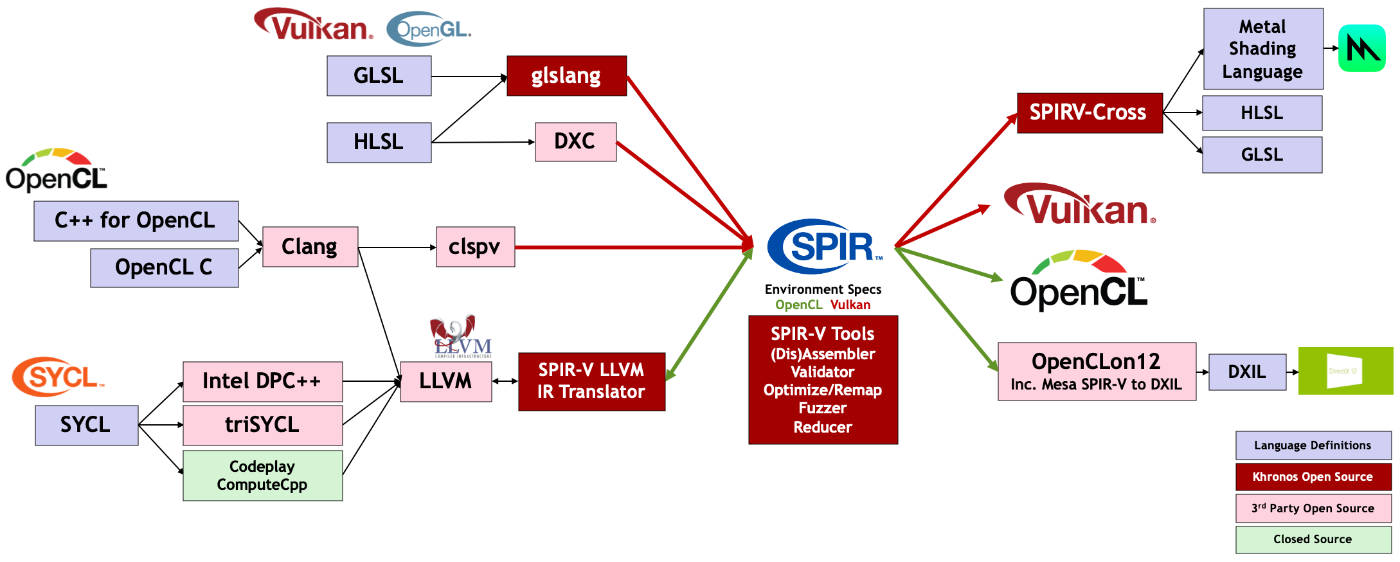
- Oct 22, 2004
- 799
- 1,351
- 136
Except for the details about the improvements in the microarchitecture, we now know pretty well what to expect with Zen 3.
The leaked presentation by AMD Senior Manager Martin Hilgeman shows that EPYC 3 "Milan" will, as promised and expected, reuse the current platform (SP3), and the system architecture and packaging looks to be the same, with the same 9-die chiplet design and the same maximum core and thread-count (no SMT-4, contrary to rumour). The biggest change revealed so far is the enlargement of the compute complex from 4 cores to 8 cores, all sharing a larger L3 cache ("32+ MB", likely to double to 64 MB, I think).
Hilgeman's slides did also show that EPYC 4 "Genoa" is in the definition phase (or was at the time of the presentation in September, at least), and will come with a new platform (SP5), with new memory support (likely DDR5).

What else do you think we will see with Zen 4? PCI-Express 5 support? Increased core-count? 4-way SMT? New packaging (interposer, 2.5D, 3D)? Integrated memory on package (HBM)?
Vote in the poll and share your thoughts!")
The leaked presentation by AMD Senior Manager Martin Hilgeman shows that EPYC 3 "Milan" will, as promised and expected, reuse the current platform (SP3), and the system architecture and packaging looks to be the same, with the same 9-die chiplet design and the same maximum core and thread-count (no SMT-4, contrary to rumour). The biggest change revealed so far is the enlargement of the compute complex from 4 cores to 8 cores, all sharing a larger L3 cache ("32+ MB", likely to double to 64 MB, I think).
Hilgeman's slides did also show that EPYC 4 "Genoa" is in the definition phase (or was at the time of the presentation in September, at least), and will come with a new platform (SP5), with new memory support (likely DDR5).
What else do you think we will see with Zen 4? PCI-Express 5 support? Increased core-count? 4-way SMT? New packaging (interposer, 2.5D, 3D)? Integrated memory on package (HBM)?
Vote in the poll and share your thoughts!
Last edited: