
- Dec 25, 2013
- 3,899
- 193
- 106
Physics Code Modifications Push Xeon Phi Peak Performance
Interesting read about a physicist who needs a lot of computation for his code to analyze some experiment. He decides to try out Intel's x86 Xeon Phi instead of dealing with CUDA. After a lot of trying out, he reaches and even surpasses Intel's performance claims of 6 TFLOPS FMA single precision, and half of that in double precision.
Sadly, the article does not finish with a comparison / evaluation of what this hardware experiment yielded. But nice to hear about this machine in action in real life (and thus real life benchmark).
Read the full article in the link above.
For those who missed it by the way, in July BK announced that their Xeon Phi had in the first two quarters (and I think the first quarter was still limited availability IIRC), they had already sold 8x 2015. Not all that surprising given Knights Corner was at the end of its life, but nice to see the momentum growing of what came out of Larrabee.
Interesting read about a physicist who needs a lot of computation for his code to analyze some experiment. He decides to try out Intel's x86 Xeon Phi instead of dealing with CUDA. After a lot of trying out, he reaches and even surpasses Intel's performance claims of 6 TFLOPS FMA single precision, and half of that in double precision.
Sadly, the article does not finish with a comparison / evaluation of what this hardware experiment yielded. But nice to hear about this machine in action in real life (and thus real life benchmark).
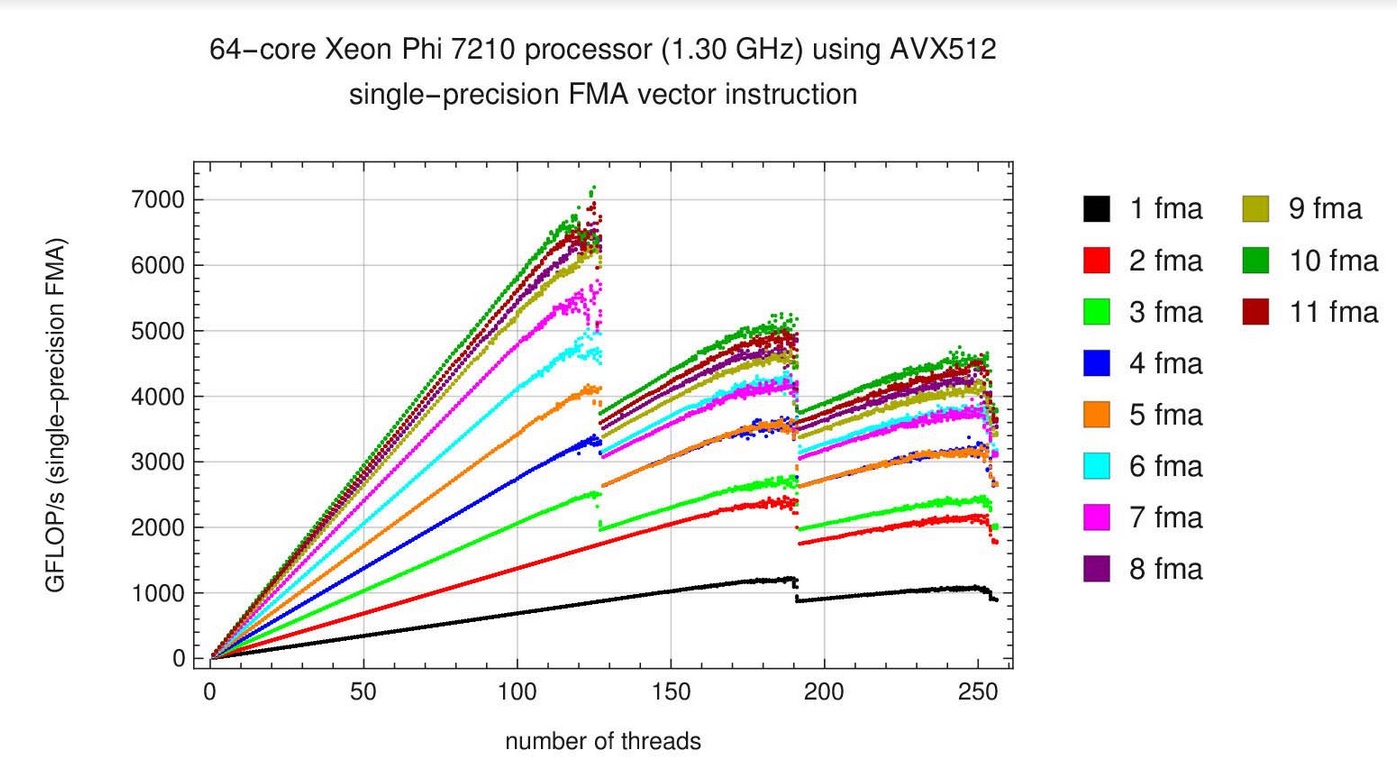
“I thought I could just write a C/C++ program with obviously vectorizable code that used OpenMP for threading, and I would have no trouble getting 256 hyperthreads to exercise 64 cores in the Xeon Phi processor. Most of that went easily, but for single precision I was stuck at 1 or maybe 2 Tflops per second for a week or two, which was disappointing.”
“It does exactly what I want and just raw computes, with no extraneous memory accesses or use of cache,” explained Dunham. In the end, Dunham said he was able to surpass the performance claims made by Intel (6 TFLOP/s for single precision and 3 TFLOP/s for double precision) by about 5 – 10%.
Read the full article in the link above.
For those who missed it by the way, in July BK announced that their Xeon Phi had in the first two quarters (and I think the first quarter was still limited availability IIRC), they had already sold 8x 2015. Not all that surprising given Knights Corner was at the end of its life, but nice to see the momentum growing of what came out of Larrabee.
Progress in the data center extended beyond our CPU product lines. Our latest Xeon Phi accelerator, formerly known as Knights Landing, continued to ramp after shipping the first limited production units in December of last year. Xeon Phi revenue grew 8x in the first six months of this year versus all of 2015, gaining share in the supercomputing and machine learning segments.


