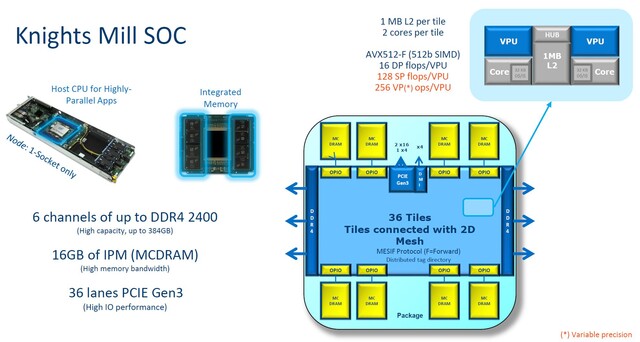
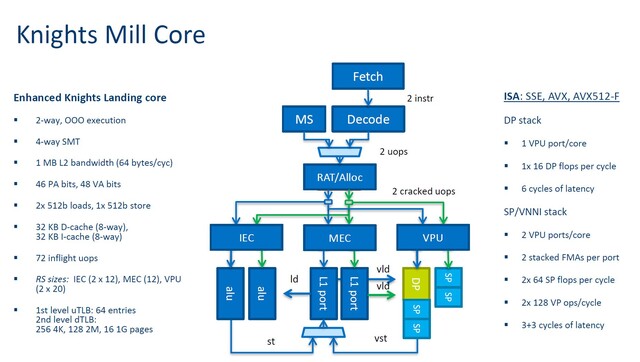
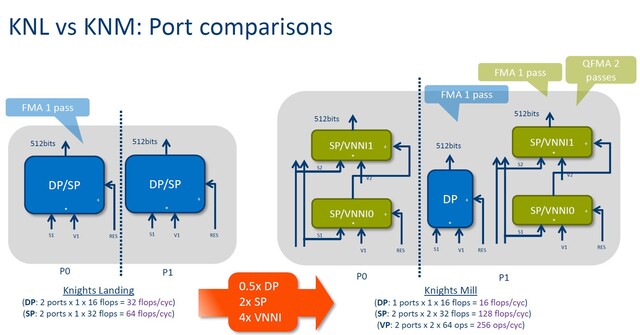
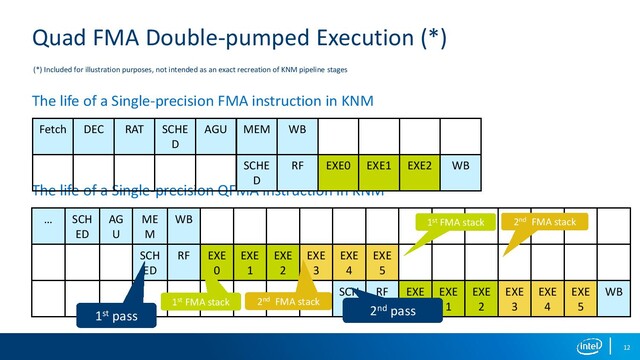
Interesting how much the diagram of Knight's Landing's execution core resembles a Bulldozer module.

You are probably referring to the image that refers to the two cores as a tile with 1MB L2 in between?
That's actually only thing it has in common with Bulldozer. It's just modified Atom cores with shared L2 cache. Bulldozer splits the execution units inside a core.
Back to Xeon Phi: Benchmarks for Nvidia's Volta accelerators have been revealed, and contrary to expectations for the Tensor core, the gains are significantly less than 2x compared to Pascal. In fact the average is closer to the difference in memory bandwidth between the two. The explanation was that Tensor operations are a fraction of the whole code.
That reinforces my belief that if they didn't have 10nm problems, and 10nm Knights Hill was released late this year, it might not have been cancelled. Note that it could have been even earlier, as even Knights Landing was delayed by half a year as well. If it was early 2017, they would have had a credible alternative to Volta.