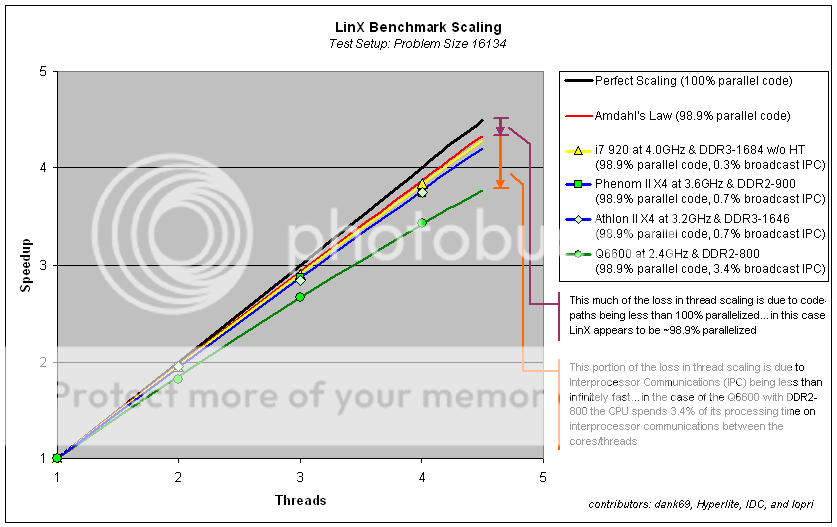
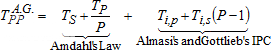I posted the same question in programmers.stackexchange.com, but got no helpful response.
I am very interested in working with multiprocessor programming and parallel algorithms, mostly for research purposes. I want to build a computer specially for this and it should have at least 8 cores (many algorithms have contention problems only starting with 8 cores).
Looking at what Intel and AMD offer I think the 8-core Intel CPUs are far too expensive, so I would have to choose between:
- 6-core Intel i7 980X (3.33 Ghz)
- 8-core AMD FX 8150 (3.6 Ghz)
- 2x8-core AMD Opteron 4248 (3.0 Ghz, server version of FX 8150)
- 1x or 2x-12-core AMD Opteron 6172 (2.1Ghz, expensive, but sometimes affordable on Ebay)
I'm inclined for the 2x8-core Opteron, but I'm not sure how the Bulldozer architecture compares to the Intel one; from what I understand the 8 cores actually share some parts and are not compleltely independent like the Intel ones (ignoring the shared L3 cache). I'm not sure that the results I get would reflect the ones that would be obtained on a " classical" CPU.
On the other side, the i7 is much more powerful and might be sufficient for testing the parallel algorithms. The 2x12-core Opteron would probably be the best for testing, but they are also the slowest by far and I would like to use this computer as a workstation too.
What would be the best solution? Is the Bulldozer architecture suitable for research (mostly for the massive parallelization of a compiler I wrote)?
I am very interested in working with multiprocessor programming and parallel algorithms, mostly for research purposes. I want to build a computer specially for this and it should have at least 8 cores (many algorithms have contention problems only starting with 8 cores).
Looking at what Intel and AMD offer I think the 8-core Intel CPUs are far too expensive, so I would have to choose between:
- 6-core Intel i7 980X (3.33 Ghz)
- 8-core AMD FX 8150 (3.6 Ghz)
- 2x8-core AMD Opteron 4248 (3.0 Ghz, server version of FX 8150)
- 1x or 2x-12-core AMD Opteron 6172 (2.1Ghz, expensive, but sometimes affordable on Ebay)
I'm inclined for the 2x8-core Opteron, but I'm not sure how the Bulldozer architecture compares to the Intel one; from what I understand the 8 cores actually share some parts and are not compleltely independent like the Intel ones (ignoring the shared L3 cache). I'm not sure that the results I get would reflect the ones that would be obtained on a " classical" CPU.
On the other side, the i7 is much more powerful and might be sufficient for testing the parallel algorithms. The 2x12-core Opteron would probably be the best for testing, but they are also the slowest by far and I would like to use this computer as a workstation too.
What would be the best solution? Is the Bulldozer architecture suitable for research (mostly for the massive parallelization of a compiler I wrote)?